| |
|
|
| �Ķ��� -> �������� -> Ϊʲô������˲��ı���������������Ҫʱ�������� -> �����Ķ� |
|
|
[��������]Ϊʲô������˲��ı���������������Ҫʱ�������� |
| [�ղر���] �����ر��ġ� |
|
����ѧ�Ƕȣ��������������Դ����Ĵ���ͨ·�кβ�ͬ��Ϊʲô���ɱȸ�ʸ����״�����У����ֵġ��������롹������ʲô�� |
|
������������漰ʱ����Ϊһ���Ӵ�ѧʱ���Ϳ�ʼ�Դ��CD�������ڣ������ֺ������������ȷʵ�����˲����뷨�����������۵���ѧ�Ҷ��㲻��רҵ�������ǻ��ڸ�������Ĺ۲��˼����˵�ò��Եĵط������λָ���� PS�������ἰ����Ŀ������������APP�϶����ҵ���û����סд�ù������������ղء����ֲ��ף���������ϲ��������ϲ�� ���ֺ����Ե�����·�� ���ֺ������ڴ�����Ҳ���ߵ��Dz�ͬ��·�ߡ� ���ִ��������Ƕ�ͨ�����С�������Ƥ��ֱ�Ӵ������ߡ����ࡢ��ɫ��ͬʱ����Եϵͳ�����ʺˡ������壩����ͬ���������������Ҫ�����Ը���ƫ�������ԡ�ֱ���ԵĴ����� �����Դ��������л����롪�����뾭������ʶ����ʻ���ȡ���������������������һ����������Ҫ�������ԵIJ��忨����Τ��������ð�ʱ��˳���������塣 ����֮��������"�쳵��"��������"������"�� ���Գ��DZ�����ע����ڸ���ϣ������������������Ʒ�����н�ͷ�ľ��Ǹ�ʣ����ճ����ⲥ��ɨһ���������£�����ȷʵ���ܱȸ�ʸ����״�����С� ������һ�����ܵĹؼ����죬�Ҿ�����"�ᄈ"�ı��﷽ʽ��̫һ���� ���ֵ��ᄈ���ֱ�ӡ����������������ˡ��������������������ܴ�̶���ͨ���������������Ծʹ�������ˡ� ����ʵ��ᄈ����Ҫ����㴦����������������˼���ٽ�������ģ���������ȡ��������ݡ������֪����һ��������˲�����г���������ױ�ϡ�͡� һ�����ڵĽ�����ʷ������ɫ��ʼ ��������Լ������顣 �ҵ�����ƫ�ñ仯�Ǵ������������֡� ��ѧ�����ر��Ծ�ʿŮ������ʱ�����绹�����������š��������硷"������"ר���İ���ȥ��CD����ʱ��ʲô���أ��϶����Ǹ�ʡ���Diana Krall��Ӣ������������СҰ��ɯ��������������� ��ĥ��һ�£�������Ӧ���Ǹ������ʸкͱ�ʶ�Ե���ɫ�� Billie Holiday����ɳ�ƴ��ԣ�Ella Fitzgerald��˿���⻬��Nina Simone��������أ�ÿһ����ɫ����ͬ������˾�����ʹ��������ʣ�������������ů����Ҳ��˲�䴫������� |

|
|
Billie Holiday Ϊ������ɫ�ӳɵģ��Ǹ��ֵ���С����������ڳ��裬���������������������¡����漰��ҧ�ֵ����ػ�����ͣ�ٵ�ǡ���ô�������ʱ��������ţ���������ij�����ڵ������ ����У��ȳ��������������� ��������������λ����Ϊ��м��ѵĴ����� ����Stacey Kent����ҧ�ּ��俼����ÿ���ʶ������ĵ������������ᵫ�����ķ������˷·�����˿��Ħ�����ʸС���Ϊ�ټ����ֳ�����ʤ��¼����ĸ��֣���ϸ��һ�����������ֻ�汾�ġ�It Might as Well Be Spring������ᷢ�����������ѹѹ������ʱ�����ܰ���ͨ�ľ��ӳ����������Ρ� |

|
|
Stacey Kent�����ֳ�¼���ر�ֵ��һ�� ��һλ��Michael Bubl�������Ծ��ӵĴ����̳���Frank Sinatra���ֶԻ������Ȼ�������ڸ������������һ��������ͣ�ٺ����������ر������־�У�����һ��ʿ����Ŀ���������������Ħ����ȫ����Ʒ�� |

|
|
Michael Bubl���ij���ͬ��¼��ר�� ��Ӧ��������̳���ﵽͬ���ε��츳���ѡ�������������������˺ͳ���Ѹ�� �����˲��ö�˵�ˣ�������������ڶ������ֵ�����Ȼ�����ϣ��ܰ���ͨ���������仯���������������ںϣ��Ӳ������ֲ������о��ڡ�������Υ�С� �ص�˵�³���Ѹ�������۳����ﻹ�ǹ��������ҧ�����ֵ�ϸ�ڱ仯����ḻ����в�Ρ�һ����ת����һ�ο���IJ�����һ��ͻȻ�����������������������������ķ���ת�ơ����ֶ������ʸеľ�������Ŀ��ƣ��������㳪���˵ĸ�Ҳ�ܳ����Լ��Ĺ��¡�����Ҫ���ǣ�������в�����������������������¶����ǿ��˽���������ڻ���Ȧ��һ������ |

|
|
����Ѹ2014������ר��������Ŀ��������� �������������������ģ��ҵĿ�ζ��ʼת�����־�ʿ��û������������Ȼ��û���ʲô���ˡ� ����ֵ��ǣ������ַ��������׳���ȥ�����ж�ʱ��������ȥ�Ƚϲ�ͬ�����ֵĴ����ʸУ����ֲ��쵱ʱ�����ɱ����������ҡ� ����Thelonious Monk�������⡰�����Ĵ������������������̴̵ִġ���Ƿ������ʸУ�ÿ���������DZ���С�����ڼ����ϣ�����һ�ֲ�ĸ��ԣ������֮�£�Bill Evans�Ĵ��������ɵ�����ë����������ʡ�С��ռ�кͺ����С� |

|
|
Bill Evans ͬ�����Ǵ���ɫ�и�����У�����������Ҿ���������ɫ�����˸���ظ��ܵ������ߵĸ��Ժ����״̬����Ϊ��ʱ���������ʵ���Ǹ������������"�ư�"����������һ�и���ֻ��ͨ����ָ�ڼ����ϵĶ�����ͨ��ÿһ�δ��������ȡ��Ƕȡ�ʱ������� ����������ϣ������ֿ������������б��������������֡����ƹ�����������ĸ��ӹ��̣�ֱ�������������������������С� Ҳ�������Ϊʲô��ʱ�����ֱȴ���ʵĸ�������˲��������ġ�����Ϊ���ߵ���������ԭʼ����ֱ�ӵ����ͨ���� ���ࣺ�����ɸ�ԭʼ����� ����˵���ر����ױ����ӵ�Ԫ�ء������࣬����˵�ɶ����ϸ���˵���������в��죬����Ͳ�ϸ���ˣ��� ������������ܵ��������ԡ� ��Զ��ʱ��������һ�����ʼ��ľ���û�ʯͷ������ʱ�������й��ɵ�����ģʽ���Ѿ��ڵ�����ͬ���ǵ�֫�巴Ӧ������Ҫʲô�Ļ�Ѭ�գ�����Ҫ�����������ĵ�һ�죬��������˾ͻ��̲�ס���Űڶ������������彫����������������α�������ˡ� �ǵõ�һ������Hotel California���������ùݣ�1994��MTV������ֳ��棬�������IJ����Ƕκ��������������ĵļ���solo������intro����Don Henley������Ƕ��ֹġ����ֹ�Ƥ���������ܺ���˵�塪�������˷ܣ����Ǽ���������һ��"�ԣ���������"�����ʸС� |

|
|
�Ĵ��ֹIJ����е������������ȷ�����Ǵ����˶��е������������ʵ������һ������ϸ�IJ��������չ����ʱ� ����"�л���"����������ʵ��������Щ���µ�MIDI���ܴ����ҵ�ԭ������ֱ�����ڣ���ȻҲ�������������رĵ����ͺϳ�����Ʒ�����硶�Ǽʴ�Խ����ost�������㣩������ƫ����ʼ�������������ԭ�������� ˵�ؽ���仯����ʱ�������ȵ��Ա仯����˲��ת������ ����������ص�Ӱ�Ƕ������ֺп������������ɣ���˵John Williams�ڲ����Է�ʱ�ڲͽ�ֽ������д�ģ�����Ҷ�����Ϥ�ɣ� ����Scott Bradlee's Postmodern Jukebox����һ����ʿ�ı�汾��ͬ�������ɣ���ԭ��4/4�ı�����ѵ�swing feelʱ����������˲���"Ӣ��ʷʫ"�����"��ҹ�ư�"�ķ�Χ�� �������ת���ĸ�֪Ч�����Աȳ�һ�ζδʸߡ� |

|
|
��Harry Potter Jazz Variations����Scott Bradlee�� ��һ�����������ر�ϲ���ġ�Por Una Cabeza����ԭ����Carlos Gardel�������Ƶİ���̽͢�꣬2/4�ĵĽ�����������������˼����Ϸ��������ÿһ�����Ķ��������ߵĽŲ��ڵذ����û��� |

|
|
��Por Una Cabeza����Carlos Gardeԭ�棩 ����һ������������������������Ԫ�İ汾���������ˡ���ר������Time Of Gypsy����������ʱ�⣩���ܿ������ⲻ���ǽ�̽��Ľ���2/4�ı�ɹŵ伪�������ɽ��ģ��������˼�����������������ʽ�������ɶ�����ôһ���죬�������Ӵ�"��������������̽��"�����"�����Ե�����ʫ�˶���"�������汾���ǵ���ѭ������������֣���ҿ��������Ա������� |

|
|
��Time Of Gypsy��������Ԫ�� ����֮��������ôֱ�ӵ�Ӱ����������������Ϊ����ӽ�������������ﱾ�ܷ�Ӧ������һ�������ֵ�����������Щ�о������Ľ����������������ֽ�������������������������С� �ٷֵ�ϸЩ����һ��ʱ��������Ҫ���Դ������߹�ϵ��������ҪԤ�������������ֱ�Ӿ����ٶȱ仯�ĸ�֪�������ǵ������ӡ�����������ͬһ��Ƶ���϶Ի��� ��������ԭʼ�ԣ�һ�����Ӽ�ʹ��������ֻҪ����仯ǡ�����ḻ��Ҳ������˲��ı����ǵ�����״̬�� ��Դ���֣�����������ɵĸ� ԭʼ����������еĸ����е����־������Ÿ����������ġ� ����Ҳ������������Ȼ��ȫİ������һ�����������ϳ���ȥ������Ҫʲô֪ʶ��������˾�����Ϊ�̵�����ɰɡ��������������ĸ�Դ���֡� ��������ĸ�Դ���֣��Dz�³˹�� ���ǽ�����ЩԽ��Խƫ���ż����ṹ���ӵ��ִ���ʿ��³˹����಼³˹��R&B��������������������������·���Ĵ�ͳ��³˹�� �������ֿ���˵�Ǵ������ﳤ�����ģ�ͨ��ֻ��19����ĩ20���ͳ������ϲ��ķ���ū���͵�ũ�������·���ء�������ɻ�ʱ�Ż�߳��� ��Щ�˴�ʶ�֣���û�ܹ�ʲô����ѵ����������Ҫ����һ�������һЪ�������ܴ�һ��й���ĵ�ʹ�ࡢ˼�ϣ���;���������û�������ź��ξ��ܼ�������֡� ���Ը�Դ�������ĵ��ص��������Ļ����롣 ���������Ļ��еĸ�Դ���˷���ӡ��ɲ�ɽ�衢�±�������һ������³˹���Ҳ���Ͷ�������������й��еġ���ͬ���ǣ������ص���ˮ�������������ص���ʷ���ˣ�����Եø��������ͷţ��������������������Σ��ֿڶࣩ����������Լ�ǿ���ܵÿ������ϵ����ˣ��������µ�������ԣ������½Կɲ�³˹�� ��������������������ֵ�ۿ�����Щ���ڻ�ʽ�²������Ǹ�������������Υ�����ɣ���������"call and response"���������Ӧ������ʽ��ԭ�������Է���ͳ���ֺͽ���ʥ�裬һ���˳���ʹ�࣬�������ú�����ο�� |

|
|
����³˹֮������New World Records�� New World Records��վ����ѷ�����һ���������¼��Ƭ�Σ�����ԭ��̬�IJ�³˹����Ȥ��С��������������Ԥ���룺���ö��������棩�� https://www.newworldrecords.org/products/roots-of-the-blues ��³˹���˵Ĺ�����������ݸ������Ļ��������Ӧ����ʽ������һ��ʼ�Ͳ��ǹ¶��ĸ��˱�����Ǽ������зֵ�������ʹ�������ʹ�࣬Ҳ�����������������ڻ�Ӧ�� ����Muddy Waters�ġ�Mannish Boy��������������������ʽ��Muddy�ȳ���"I'm a man"������ô���ں��Ӱ�����Ȼ�����Ϳ��پ�����������һ����Ӧ�����·���˵"���ţ�����"�����и����͵�Lead Belly�ġ�Goodnight Irene��������һ���ں͵ĸо�������һȺ��Χ������һ������˵���£���������"���ţ����Ƕ�""��Ӵι���ɲ�����"�������������蹲���Ͱ�ο�� |

|
|
��Mannish Boy����Muddy Waters�� ������һЩ�����������졪��ʲô·�ӵĶ��У��ŵ�ġ�ҡ���ġ���ҥ�ġ�����Щ����ر�õģ���˵�Լ��ᾭ����ȥ�����ָ�Դ���֣���³˹���Ʋ���������֮һ�� ���Ҫ�����������ͣ����õ�����������ϵ�������������Ǹ��������Ӧ�Ľṹ��������Щ��ֱ�Ӵ�����з�Ӧ������������blue notes��������Ҫ�ǽ����ȡ�����ȡ����߶ȡ���Щ�������κ��Ļ������¶��ܻ���һ��˵��������˻����������ij�ֹ�����е�ԭ�͡� �����ص���Dz�³˹�IJ��������ŵ������������г������³˹��������Щ�Ȳ���г��Բ��������������������һ��ʼ����˵�Ի����������Ӧ�Ķ�̬�����������̡����ֽ��ڴ����С��֮���ģ���ش���Ҳ���ö�Ӧ��������еĸ����ԡ�������ʹ��Ҳ��ϣ�������о���Ҳ�м��͡� �Ӳ�³˹���ٿ�ʼ���֮�� �ðɣ��һ�����ô���ī���ܲ�³˹�������밲�������Կ��� ��ô���أ��Ƽ��Ӳ�³˹���ٵĴ����ֿ�ʼ�� ���ֿ��ٺ�����Сʱ��ѧ�ĸ�����������������������������19���ʹӵ¹������������������й��ģ�ÿ������������Ƭͬʱ������������������ɫ�����ʺ����ࡶ�ͱ𡷡����������������ҥ�� ����³˹���٣�ͨ����ʮ����Ƭ�������������Ķ�����רΪ���︴����ж����� |

|
|
Hohner����֪����רҵ��³˹����Ʒ��֮һ �����ص�ѹ����bending�����ɾ���Ҫ�������������Ͽ�ǻ��Ļ���Ч����ģ��������ԭʼ����б����������̾Ϣ������ʱ�����������������������ִ����������䵽�������ߵ�����ʱ�������д�����е�ԭʼ�����˲�䱻�����Ϊ�Ǿ������Ǵ�Ӥ��ʱ�ھ���Ϥ��"ʹ��"����ģʽ�� ��³˹������Ʒ�����Զ���ͻ������������������������ӣ��������ٴ�ʦJean-Jacques Milteau�ġ�Fragile���͡�Blue 3rd���� ǰ������������ִ��������͵�ì����С���������ʱ�����Ҫ�ϵ�������ʮ�㣬ͨ��ѹ�������������"��ǻ"Ч������������ѹ���������������������ͨ��������Ϣ��������ɫ�Ϳ��ٽ���仯������һ���ر��������ѵ����С������ף�һ�����һ����ţ������˦������ֱ�Ӽ�����в��롣 ţ�ƵIJ�³˹�������࣬�������ˡ�����㱻���л��Լ�ȥ����ġ� |

|
|
��Blue 3rd����Jean-Jacques Milteau�� ����������һ���ں�����ɫ�����ࡢ���ɵ��ִ������Ʒ���һ��Ƽ�Joe Strummer & The Mescaleros�ġ�Mondo Bongo��������¼��2001�����š�Global a Go-Go��ר���У�������Ϊ"��������Ķ�Ԫ�Ļ�����"��Ҳ��ѡ����ʷ��˹����Ӱ���֣�OST�����ҵ��� ����һ�dz�����ɫ���ں���Ʒ����������Ϊ���ף����������������ȶ�����Դ�ĸ�����Ԫ�ء����ڴ���ʹ��ԭ����������ɫ�ʸ��ر����������Ȼԭ�������о���ǰ���ᵽ��"�л���"�� |

|
|
��Global a Go-Go����Joe Strummer & The Mescaleros�� ����һ�����ں���Ʒ���������Ѻ�Bobby McFerrin�����ġ�Hush����Bobby McFerrin����Ҳ֪���������Ǹ��������ģ���������������������ֶ�Ч�����������˹��ţ�������ľ��ǡ�Don't Worry Be Happy���� ��Hush�����������ر�����˼����Ϊ��չ����������ȫ��ͬ���ֱ�����������������ҵ���ͬ���Եġ���������ů���л��Ĵ�������ɫ�ͼ�������Ľ���ѿأ�����Bobby���ּȿ��������ɡ��ֿ����ǽ��ࡢ���������Ǻ��������������������һ��һ��һӦ��һӦһ�͵ĶԻ�Ч�������������ǵ�Ƥ���������������͵���������̧�ܡ� |

|
|
��Hush��(�����Ѻ�Bobby McFerrin) �Ұ�����Ҳ��Ϊ��Դ���֣���Ȼ����������ʷ�����ϵĶ��壬�������Լ���Ϊ���ص㡪��û�и��ӵı������ż������ǰ��������Ա�Χ��һ�����ӱ���ļ��˱��ݵĸо��� �����Ƽ�����Щ��Ʒ�������ڲ�³˹���ִ��ںϣ����Ƕ����ָ�Դ�Ե��������������ֱ�۵ظ��ܵ�Ϊʲô���ֱ����Ը���ֱ�����ġ����������ӵ���������Ϊ����������ֹ�ͬӵ�е���Щ������С� ���Ե�ħ�� ˵�����ת�������ֵĵ����Dz��ܲ���һ�µġ� ������ֻ��֪��Ƥë���д���һ��רҵ����������̵��Ե�������ʣ���Ҳ����ϻ���ֱ����д��һ�š����տ��֡���С��ת���档�ҵ�ʱ����ѧ���٣���������һ�������̾������˵��Ե������� ͬ�������ɴӴ��תС������������ӡ���ף����䡱�������������տ��ָ衷���ˡ����ղ����ָ衷��ת�����ֱ�ۣ����������͡� |

|
|
��������һ��С���ġ����ղ����ָ衷�� Ȼ������������Щ�����ӵ�ת���汾���������Լ���������Ĵ��������������ֱ���棨���ò�˵��ʿ���ֻ����������ǿ����������ת����������Ƶģ�����֮��������������ޱȻ��֡� ����˵���Ծ������ֵ���л��������е�������Ӿ�ȷ�ͳ־á� ����Ļ��и��ֵ�ʽ���������ǵ�ʽ����С���������ִ���ϣ�����������J�ǵ�ʽ���������ظУ��������ǵ�ʽ�ȴ�����������ɡ�����Miles Davis�ġ�So What���õĶ����ǵ�ʽ���������б��������ţ�Bill Evans�ġ�Waltz for Debby���ڴ�����ִ������С��ɫ�ʡ��⼸������Ȥ�Ķ����������������� |

|
|
Miles Davis��̱�ʽ�ġ�So What����������������ܵ�����ṹ �����������飬�Ҳ������ֵ����������Ƿֲ�ģ� ��һ�㣺�������� ����ֱ��Ӱ�����ʺͺ���Ƶ�ʣ���ɫ�ķ����ṹ�������干������̬�仯ģ����е����������������ֱ���˵��ķ�Ӧ����������Ҫ���Դ����� �ڶ��㣺ԭʼ���ӳ�� ���Ժ����̹�ϵ�������ǽ����������γɵ���з�Ӧģʽ���ض���ɫ�����粼³˹���ٵĿ�ǻ��ֱ������������ԭʼ����б��﷽ʽ��ijЩ����ģʽ�ܻ��������������ļ��䡣��㷴Ӧ�ƹ�����֪�ӹ���ֱ��������ࡣ �����㣺�Ļ�����˼��� ���������ͨ����Ϊ�����ָ�����Դ�����ض���Ŀ�����ĸ��˾������Ļ�Լ���׳ɵ���к��壬ͨ��ѧϰ���۵����־��顣��������Ϊ������DZȽϱ���IJ��֡� ���Ե���"Ϊʲô������˲��ı�����"ʱ���ۺ������ҵĿ����ǣ����ֲ�������������Ҫ�������ӵ���֪�ӹ����̣�����ͨ���������ͬʱ���������ǣ����кܶ�·������ֱ���������Ŀ쳵���� ��Ȼ�����϶��Ǹ��˵Ĺ۲�����⣬�϶��в�ȷ�ĵط��� ���ֺ���еĹ�ϵ�����ͺܸ��ӣ��漰��ѧ������ѧ���Ļ�����ѧ�ȶ�������������ָ����������ֱ��������ˡ����������������ճ��������ܽӴ�������ӽ�ħ���Ķ����ˡ� ������£���֪��ϣ����Щ�������IJ�³˹��ӣ��Ƚ������漸���ɡ� |

|
|
Buddy Guy - ��Aint No Sunshine�� ������δ������³˹������������Buddy Guy�汾�ġ�Ain't No Sunshine�����������������Ƿ������Ŀ�ζ�����������겼³˹��������¼��2000��ĵ�Ӱ��ŵ��ɽ����Notting Hill��ԭ�����У������������ʧ����¶���������������һ������ʧȥ���˺���������ʹ��������� �������������ִ����������һ�ס�What Kind Of Woman Is This?�������з磬Ҳ�ܰ���һ���Ƽ��� Ҫ�����������û��������ǾͿ��Լ���̽������ |

|
|
��Midnight Blue����Tinsley Ellis�� Tinsley Ellis�ķ����Eric Clapton�dz����ƣ�ͬ��Ҳ�Ǹ����Ķ��⼪���֣�soloʱ��ʶ�Ⱥܸߡ�����Ϊ��������Ҳ��Է����ִ����ڵĿ�ζ���ż��͡� ���š�Midnight Blue��ר�������ֳ�ɫ���������Ƽ�����Ŀ�ǡ�Kiss Of Death����������������뼤�飬����һ����������̹�Ͻ����Լ��İ�����ʧ��Ĺ��£�����һ���Ҿƣ�Ũ�Ҷ������� |

|
|
B.B. King -��The Thrill Is Gone�� �����������ʦ���ڡ���Щ��Ʒ���ܹ���Ҳ��ԭ֭ԭζ�������ִ����ڿ�����Ҫϰ��һ�¡� ������B.B. King���쵱���IJ�³˹֮������������Ȼû�����������֣��������������������ʱ�е������������˵����Ҳ��һ�ݹ��ͣ����� ���Ĵ�����֮һ��The Thrill Is Gone����һ���ڽ���ֿ���ѱ�ľ���֮�������Ѷ�����ϸ�����б���Dzں���������д�ա������еļ���solo���ֱ���Ϊ�������в�³˹�;�ʿ���ֱذǵ�ѧϰ���ϣ������İ���"Lucille"���dz�Ϊ��������³˹��������� |

|
|
Howlin Wolf - ��Smokestack Lightning�� Howlin' Wolf�Dz�³˹���ڵĿ�����֮һ����������ɤ����ǿ�ҵı��ݷ��������� ��Smokestack Lightning������1956��ľ�����Ŀ�������ʱ���֪��������������Щ�ִ�������˵�������׳¾ɡ�Ʈ���Ź��ϻҳ��ĸ衣δ��ʮ���ö������ܳ�ָ���ԭʼ�IJ�³˹ζ�� |

|
|
Koko Taylor��Wang Dang Doodle�� Koko Taylor����Ϊ��³˹Ů��������ǿ������ɤ���ͳ������е��ݳ�������������Wang Dang Doodle����һ���ɶ��ḻ������ץ���Ĺ����������������Dz�³˹�������ǿ�������ž�����С�ƹ���������ǻ��ۣ����ű��ӱߺȱ�һ�����ľ�ذ�ҡ�ڡ� һЩ��չ�Ķ��� ��ӭ�����������վ����䡣��������ǻ���������������������������ϲ�� �������ϵͳѧϰ��θ��õغ��Լ��ദ����ӭ���ġ������������ֲᡷר�� ?? ����@���꣬Flowtalk���̰֡����ϲ������ش𣬻�ӭ�·�����ר��������˵��?? ������ ��û�������������һ�����߰� |
|
����Ϊ�����������Ҫ�������Dz��ǡ�����Ϊʲô���ģ� �����ʹ�ô���������ʹ�øߴֲڶȵ���������ʹ�ò���г���̣���ô���ֲ�����֤��˲�䡱�ı��������ر����ھ�����������ֵ�ģʽ��������˵����Ϥ������¡��˶Դ��������ߴֲڶȵ������Ͳ���г���̵ķ�Ӧ�Ƿ��䡣���Կ�����Ϊʲôһ�������վ����е�����������ֵ���̬�������ܶȵ����ֵ��Ӿ�ģʽ������������һЩ�˵�ע�ⲢӰ�����������˶��ܼ���Ť����Ѫ�����ǿ�ҶԱ�ɫ�����ֵķ�Ӧ�Ƿ��䣬����һЩ�����Ǻ���ϰ�õġ����Ļ�Ӱ�졣����ֱ�۵��Ӿ�ģʽ���������˿������ֵ�������Ӱ��������������Ȼ����ҪһЩʱ�����˶����ֽ���ʶ��ʹ�������������ʱ����ȫ���ܷdz��̶����˵��ɡ�˲�䡱�������磬һЩ���߿��� 114514��1919810���ߺ߰������������ͻ����ɵط�Ц������Ұ���ȱ����Ļ�ģ����ɵ�Ӱ�졣����Ҳ��������������������棬�ڵ绰���Գ������������ƶ�����������֪������ʲô������������Ц������ ANN �ı������ձ��Ѿ��е���թƭ�Ż�ע���һ�㣬���������������ɸѡû��˵��Ұ���ȱ�����Զ��Կ��ܲ��˽������¶������ϵ����ˣ��ر��������ˡ� ���ִ��п�ʶ�𡢿�Ԥ���ģʽ�����������ġ����ɡ������ȣ����ܹ�����һ�����������������ص����������ǣ���Ⱥ�д���һЩ���������ɵĸ��壬���ǵ�һЩ�ṹ���ڲ�ͬ�� һ��ʵ���� 205 ��������ת�������ɱ���Ƶ�����ϵĿ�����ť��ѡ��ͨ���������ݵ����Լ��е����ö��������������ʾ�����������ѡ���� 399 Hz Ϊ���ĵġ�Ƶ����Խ�խ����ΧԼ 350 Hz����Ƶ�ʡ��˶�Ƶ�ʵ���һƫ���ƺ������Ա�������Ӱ��[1]�����ֵĽ�������Ӱ��һ�����˵����������Ƶ�ʣ�������������ٿ��Ա����Խ���Ϊ�˷ܣ���֮����Ϊ�滺��2025 �꣬һ���о����Ե�ͼ���˶����������֣����ֵĽ���Ƶ�ʽӽ����Ե� �� ��Ƶ��ʱ�������ߵ�ǰ��ҶƤ��ᷢ��ͬ���������˶�Ƥ�㼤�����ܵ������Ǹ������ִ����ӡ�ҡͷ���ԡ����衣���ֵĺ��������շ�Ĭ��ģʽ����� �� ��������г���̿��Լ������ʺˡ��������Harding, Eleanor E., et al. ��Musical Neurodynamics.�� Nature Reviews Neuroscience, vol. 26, no. 5, May 2025, pp. 293�C307. nature.https://doi.org/10.1038/s41583-025-00915-4���������ԣ����Կ��Լ��������������е�ģʽ�����ٴ���������������ʱ��ʶ����Щģʽ���������������������Ԥ�ڵ�ģʽ��ͬ����ô���ǿ��ܻ�е����Ȼ����־塣�������Ե�ģ���ܸ����˶Ժ����ö��̶ȵ�����[2]������ǿ�Ⱥͽ��������仯������������������ǿ��������Ӧ����Ҫ��ʽ֮һ��Huron��2006 �꣩��������Ԥ�ⱻ������֤Ϊ�нϸ�ȷ��ʱ���ܻᴥ������ϵͳ�����˸о����ã��ϵͱ�����Ԥ��������������ʸж����������˷��У��ñ����д��о������ܽӽ� 15%.�ο�^Patchett RF. Human sound frequency preferences. Percept Mot Skills. 1979 Aug;49(1):324-6. doi: 10.2466/pms.1979.49.1.324. PMID: 503755.^https://doi.org/10.1016/j.bica.2017.09.001 ������ ��û�������������һ�����߰� |
|
֮����������˲��ı�������������Ҫʱ��������Դ�ڶ��������ڴ��ԵĻ��ơ���֪·������мӹ���ʽ������ء� ���Ƕ�������������ʱ�̣������ָ߳�ʱ������ͻȻһ��������������������̲�ס����ӯ���� |

|
|
�����ֽṹ��������Ӧ��ʵ֤����?����ƪ���Ĵ�������֪ѧ�ĽǶ��о��������о�����ʲô���������������Ϻ������Ͼ�ķ�Ӧ�� ��������83�������ˡ�������дһ���ʾ����������ǹ�ȥ����������ʱ�����巴Ӧ�� ���: �����������Ӧ�Ǽ���������������ߺ���������С���Ц����Ƥ�������������Ҳ��Ϊ������ �о��߷����ض������ֽṹ���п��������ض���������Ӧ�� - ����ͺ���������г�����ԭ���ǣ� a. ���б�����������������Ӳ���г����г�� b. �½������ѭ������Ӫ���˾���ġ��ؼҡ��У���һ�������Ľ���� - ��������Ƥ���� a. �������ĺ��ҵij��֡� b. ��������ɫ�ʺͽ����ͻȻ�仯�� c. ����ת���� - �������٣� a. �н���ļ��١� b. �з����� ��һ���й��������飺 һ����Ϥ���������̰�������ij��˲�䣻 ���Ž��༤�ҵ����֣���ͻȻԾԾ���ԣ�����ʮ�㣻 һ��ѧϰһ�߲�����ĸ赥�����Խ��Խ���� ��Щ�������ɺϡ� ��ѧ�о����֣����ֲ������ⲿ�����������Ǵ��Եĵ��ڹ���֮һ����Ӱ�����ǵ�������������ע���������������ͺ������ɡ� |

|
|
�����DZ����Ը����ϵġ�ȫ������ �ӽ����Ƕȿ������ֿ��ܱ����Ը�����������������С� ��Ӱ���о�������������������ʱ�������в���ֻ������Ƥ�㱻������Ǽ�����ȫ���������� ǰ��ҶƤ����������ֵ�Ԥ�⣬��Եϵͳ�����ʺ˸���������Ӧ�������ͻ�·��ͨ����Ͱ��ͷŴ������øС� �����˾�����ǣ����Զ����ֵķ�Ӧ�����ǡ��������ա��� ��ѧ�ҷ��֣�����������ij������ʱ����������ص���Ԫ������֮���Ƶ�Ƶ�ʷŵ磬�·����ǵ������Ϊ�ˡ��ڲ����ࡱ�������� ���仰˵�������ֲ�ֻ���ö��䣬���Ժ����屾��Ҳ�ڡ����족�Ƕ����ɡ� ������ˣ���ʹû�и�ʣ�����Ҳ�ܻ���ϸ�帴�ӵ��������顣 �����Դ�����֡����ˡ�������ϣ����������������˵�Ļ����빲���� ���֮�£�������Ȼ�ܹ������������ݣ�ȴ��������ȷ����������ȡ������֣�ǡǡ�ֲ�����һ�հס� |

|
|
�����ܵ�����������Ϊ��ϵͳ�ļ��� Ϊʲôһ�װ��˵ĸ������������ᣬ�������������˲��������飿 ��Ϊ������ʱ��ǰ��ҶƤ�㲻������Ԥ����������ͨ�����Եġ�����ϵͳ���ͷŶ�Ͱ��������Ǹе����������˷ܡ� ���ͬʱ����Եϵͳ�е����ʺ˸���ʶ�������е�����ɫ�ʣ�����������Ƥ����������������������ͼ������������� ���⣬���ֻ���Ӱ�����ǵ��������ɡ� �о����֣�ÿ�컨10�C30���Ӿ������Լ�ϲ�������֣���������Ч���;�Ϣ���ʡ�����Ѫѹ������������ߡ����ʱ����ԡ���HRV��һ��������Ľ�������Ҫָ�꣩�� ��һ����ı����ǡ�����-������ϻ��ơ��� ����ͨ��DZ��Ĭ���ظı����ǵĺ������ࣨ�����滺�����յ������������Ӷ����������ϵͳ���������Ƿ��ɡ��ȶ������� ����ζ�����ֵ���������Ч����������ȫ���������۸��ܣ����Ǹ�ֲ�����������Զ����ػ����С� |

|
|
��������ֿ��Ե�ȼ�ж�ϵͳ �����ϰ�����˶�ǰ��һ�����ǿ�ҵ�������������ô���Ѿ��������м����˴����еġ�����ϵͳ���� ��ѧ�о����������������ǿ�������֣�ͨ����ÿ���ӳ���140�C150�ģ�����������������ǵ��ж���Ը�����廽�Ѷȡ� ��Ϊ�������������ʱ�������п���������Ϊ�Ļ��ڣ�Basal Ganglia���ᱻ�����ʹ������Ҫ�������� ͬʱ��С�ԣ�Cerebellum��Ҳ����ݽ������������˶�Э������ǿ����ͬ���С� ����Ҫ���ǣ����ֻ��ܴ�ʹ�������ء�ȥ���������صȼ��ص��ͷţ����������������е������������� ���Լ�ʹ��ֻ�����������֣��Ƕ�����Ҳ���������ƶ���ӡ����Ρ����롰�ж�״̬���� ��Ҳ��Ϊʲô������˳������ڽ������������ڵ�ԭ�� |

|
|
�������ѧϰ���������������Ǹ��ţ� �ܶ���ϲ��һ��������һ��ѧϰ����ѧ�Դ�����ȷ�𰸣� ѧϰʱ����ѱ������ǡ��������� �о����֣������ǽ�����Ҫ��רע������֪�������Ķ������⡢���䣩ʱ��������������к��и�ʣ� ������������Ϥ��ϲ���ĸ�ʣ��ͻ���������ͷ���С���������ݲ���������������Ϣ�ӹ��������ȡ���̡� ���֮�£����������ֻ����������������40Hz˫�����ĵȱ����������ڲ��������Դ�����ǰ������ǿע������ �����������ѧϰ�ļ�Ъʱ�䣨��30����רע��Ķ�����Ϣ������ϲ���ġ��и�ʵ����֣��������Լ����ϵͳ����������һ�ֵ�רעѧϰ�� ���ֽ����л��������Ч�ʣ�Ҳ��ѧϰ���̸������øС� |

|
|
��ѧʹ�����ֵ�3��ʵ�ò��� �����ͺ�������֮�⣬������3����Ч�������ֵķ�ʽ�� 1. �������� ����ȱ�����������뿪ʼѧϰ���������߶���ʱ������10�C15���ӽ������졢���ɼ��������֣��������>140 BPM�������Կ��ټ����ϵͳ����ǿ�ж���Ը�� 2. ����ѧϰ�� ��ѧϰ�����ڼ䣬�������ֻ������������豳��������ѡ�����������������40Hz˫�����ģ�����������֣���ѡ����ʵĴ����֡� 3. ������������и�ο �����ǵ���������ǿ�ߡ� ����ʱ���������ֲ�һ����������ۣ������������ͷ������������� �Ŵ��ˣ���ͨ�����������ֻ���������У��ܰ������ԡ��������������������е��ͻ��� ��Ϊ�ⲻ�ǡ������ۡ������ǡ���Խ���ˡ��� �ؼ���ѡ���뵱ǰ������ƥ������ֽ��������ɫ�ʣ���������״̬�� ������ ��û�������������һ�����߰� |
|
�ϳǷ��������DZ���������������ʱ����500������ӣ����������������˶�ʮ���ף�ȫ������ 13�գ����˾���ʱ�������ص�һƬС���Ŀ���������һֱ�ں������š�������16�գ����Ѿ������ˡ� 16�����磬���˺������ˡ������������ӵĶ�Ա���߹�������ʼ�ھ�Ա�Dz�ͣ���ڳ�С������С����ͷ��Ȼ��һ����Ա������ȥ�������һ�����ӣ��������ǵڶ����� ������ʱ������������˯����ȥ��Ҳ������˯�������ƣ�СС��ȭͷ������ǰ�����ǵ���������ɫ�ĺͰ�ɫ�ģ�����Ǻ�˵���ζ�� С�Դ������廹�������ģ���ЩС��������������ͯʬ��������СŮ��������С�裬ÿ�������϶�����������ɫ�IJʴ��� ��Ԯ��Ա�����Ƿŵ�������IJݵ��ϣ�һ��Χ�ڷ��������������ͻȻ�ſ�����ͣ�Ȼ�������˲ݵأ���������СŮ���ĸ��ס� һ������������߹�ȥ����һ�ۣ�������������ҵĺ��Ӱ�����������������Ҳ�����������������Dz������������˵ĺ��ӡ� �������˿�ʼ��ɽ�����ڿӣ����Ǻ��ӵ�ʬ�ͷ���һ�ߡ�һ����������һ������ˣ����Ѻ���ʬ�ױ����ߴ������¿�ʼ�ھ� ��һ�������Ծ���ԭ�����ţ�����һ��б�£�������̫���ڣ�ÿ��һ����б���ϵ������������һЩ�������߹�ȥ����˵��������Ĭ���������˲�ͣ���ڣ�����Ҳ�ڲ��á� ����������ֺ��п�һ�桷 �������ˡ����죺 ����һ������ �����ô���� ������������ ��˫�������� �����������羰���ĵط� ������һ������ ��ɽ�� �����Ǹ����� �ٿ������ְֵ���...... ������һ�����ֺ�һ�裬�������꣬Ҳ�����ú�������ƪ�ش����Ľ��ۡ� �����ַ�������֮ǰ��������������������������ԭʼ�������źţ�����ͨ������ֱ�����ʺˣ��������ࣩ��ֻҪ12-50���룬���ܴ������ܿ־�����������ֲ�Ƭ���֣��� ���̾��ǣ������������� ����������˼������ ֱ�ӳ��������������ģ����ʺˣ��� �����㱻ͻȻ�ŵ�ʱ�����ȼ�к�˼��һ������������ͨ·��Զ�ǡ��ȶ��֣��ٽ��������� ������������֪ƿ���ģ��������ֵ���˼�辭��4�����裺�Ӿ�Ƥ��������� �� �ǻ��������� �� ǰ��Ҷִ������ �� ��Եϵͳ������Ӧ�� �ٱ�������ǰ�и��������֣���Ҫ�����۾�ɨ���������������Σ��Ǹ���Ȯ��+�䣬֪����д���ǹ��֡� ��Ȼ����������и��С��ǻء������ַּ�վ������ֵ���״����������˼�����һ�𡣿����������֣��������뵽�� -�����ǡ�g��u�� -ͼƬ��ë���Ķ��� -��ҵı��������ơ� �۽������ǰ��Ҷ��ʼִ�о������⣺ -����д���ǡ��ù����� ����ɰ��塣 -���д���ǡ���ҧ�ˡ��� �����Σ�վ��档 �ܴ�����������Եϵͳ������Ӧ�� -�뵽�Լҹ����� ���� -�뵽����ҧ�� ���� ��1��4�����Զ��־�������ˮ�ߣ�������״�������˼��������;��������㿪�Ļ����ܡ� ������������300�������ϣ����������仺����Ϣ�� ��������������ֻҪ12-50���룬����ʶ��֪��10�����ϡ� �����е��������ġ����״��롹�������ƹ����Է�����ֱ����������ס��ı��ܡ�����Ϳ�������������˷�������� ���ֲ��У�����Ҫ˼����Ҫ���롣 �����־���˼��֮����������������������ǿ�ң����־á� |
|
0. ���ԣ� �������Զû�п�������ô�� ��ȷ��������ֱ�۵�ӡ���У����ֱ����Ը��߸�Ⱦ���� ����һ�죬������ȶ��ˣ����ʾ�����Ҫ��ɽԽ����ִܵ����١� ������ϸ�룬���������ô�� ������˼�����¼������⣺ �����е����ֶ�������˲��ı�����������ֻ����Щ����Ϥ����ϲ�������ֲ�������ܣ���������һ������ж��ĸ���ʱ�������ģ������ɻ��Ǹ���أ����������ĸ��ȥ����ֻ���������࣬���軹�����״���ĸ�ô�����������İ���ȥ����ֻ�������и�ʣ����軹�����״���ĸ�ô������ϲ�������ĸ�����������ϲ����������Ϥ���ɵ�������ʵ��������������������ϵĴ���һ����ô�����������и�ʵĸ���������Ĺ�����һ����ô���и�ʵĸ���Ӧ������һ������������һ�����������أ�����ʲô�����֣�ʲô�����ԣ� ��������Щ����������ɻ���������⣬���������������У�����ͱ���֮������Ŷ�ô��IJ��졣 1. ���������ԵĹ�ϵ��������������Ϊ��������μ����1.1 ���������Թ�����ͨ· ����������Ϊ�������������йأ������������ԵĹ��ܣ������Ƕ���������ѧ�����ྮˮ������ˮ�� ����Щ����о��У�Խ��Խ���֤�ݱ��������������������Ǵ����й�����ͨ·������д�����Ҳ�������ֻ������л���ʽ���������졣 �����֪������һ�ֽ�����ʧ��֢��Aphasia��������ϵͳ���������߱���Ϊʧȥ˵�����Ķ���д����������������ȴ�����ܵ�Ӱ�죬���ּ�������������Ҳ�������з�ȼ������£�����Լռ���˿ڵ�0.1�C0.4%���ҡ� ����ܲ�֪�����ǣ�����һ�ֱ���Ϊ��ʧ��֢��Amusia�����ļ��������߱���Ϊ��ʶ�����ɣ�ɥʧ������������������ߵȣ����������������ܾ������� ��ͳ�ƣ�ʧ��֢����Ⱥ��Լռ���˿ڵ�1.5%�������Զ����ʧ��֢���ߡ�[1] ����ʧ��֢�Ļ��ߣ������Թ���Ҳ���ܵ�Ӱ�죬�ر����������ԣ�tone language����ʹ���ߣ��������ǵĺ�� ������ͨ�����������������������ĸ��֣�����ma������ÿ����������Ӧ����˼��ȫ��һ���� ��mother��book��Щ���ʣ���������ʲô���������������Ǹ���˼�����ᷢ���仯�� �����������Ե����⣬��Ҫ������������֧�ֵġ� ��˵������ֵ�ʱ����Ҫ�и��������Ĺ��̣�����������������������Ҳ��û�취�ܺõ�������ͨ����[2] 1.2 ���������������Ӱ������ٽ� �����������̷������룬��ͻᷢ�֣����ǵĺ���ĸ��Ϊ���ǵ�����ѧϰ�ṩ��ǿ��������buff�� ĸ��Ϊ��ͨ�����ˣ������ߺ����̵ı�������У������ֳ����ߵ�ȷ�Ժ������Ӧ��[3] ����ĸ�����У����о������еı���Ҳ����������������������ĸ���ߵı���[4]�� �������������̶�����ͼ��ʾ�� |
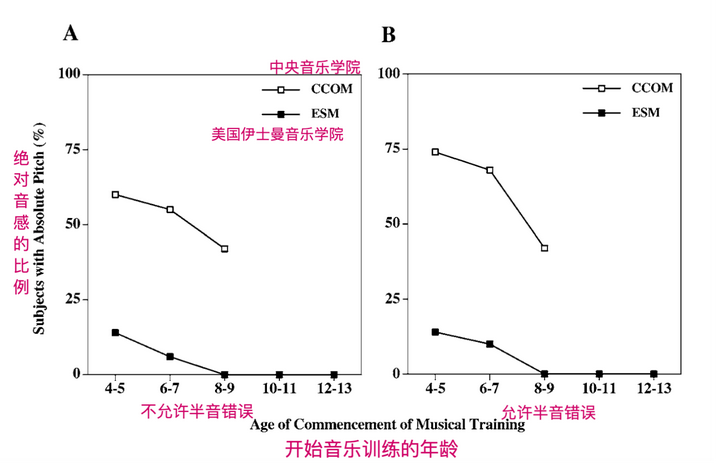
|
|
�������ⷽ�棬����Ҳ���ظ��˵�̫�硣������ͨ����������������������ʵ���ٵģ�̩������5��������Խ������6��������������������������9���� ����֪�����������֪ʶ�㣬���������Ϊ����Щ����������������ʱ�����dz���һ���� �ܹ�����ѵ�����ˣ�������������ʶ������������Ҳ��ǿ��������ע������Ӧ���죬Ҳ���ܴ��������������ʶ���м�ֵ����Ϣ��[5] |
|
|
��������ѵ����ʱ��Խ��������������������Խ���ԡ� ����֮�⣬�����о������������ھ�����������ѵ����������������ʶ������Ҳ��õ�������[6] ����6��������ѵ����8���ͯ���Ķ������������������������������������ڽ��ܻ滭ѵ���ĺ���������û�й۲쵽����������[7] ���� 1.3 ����������������ٽ���OPERAģ�� ������������Դ������ѵ��������֪�������磬��ע������������ij������졣 ����ѧ���ǽ��������ϵͳ���������һ��������������������OPERAģ�ͣ����������ֺ�����������������ٽ��Ĺ�ϵ�� ���������Ϊ�������Ǵ����У����ֺ����ԵĴ�������ͬһ������·�����ص���Overlap������ ��������·�ϣ����ֶԹ�··����Ҫ����ߣ�����ȷ�ԣ�Precision���������Ϊ���������ֿ���������ʻ�����DZ����������·�ɸ��ٹ�·�ļ�����˲���Ҫ��ô����·��������Ҳ���ܵĸ���˳���� ��������·�ϣ���������һ��쭳��Ĵ̼��У������Ծ�ֻ�Ǵ�A�ص�B�����������ظ�������Ȼ�����ָ��������������������ٹ�·�ˡ���У�Emotion�����������õ�Խ�࣬������·����ʩҲ��Խ���ƣ� �����Ǿ��С��Զ���ʻ�����ܵģ����������������ǻ��Է�����ij�����ɡ��ظ���Repetition����������ظ�Խ�࣬������������ٹ�·������Ϥ�̶�Ҳ��Խ�ߣ� ��쭳������Ȼ���ע����Ҳ������и�����Ǻ���Ȼ�ģ���ͽ����˸�Ͷ���ע����������״̬��ע������Attention������ �����ܽ�һ��������̵���Ҫ��ܣ� �ص���Overlap�����������������Ե�����������ص�����ȷ�ԣ�Precision����������������У����ִ����ľ���Ҫ�������������У�Emotion������������������ֻ����������ǿ����С��ظ���Repetition������������������ֻ�ظ�����Ƶ����ע������Attention������������������ֻ��ע�����ļ��й����йء� �������ÿ��Ҫ�ص�����ĸ����������ˡ���磨OPERA����������ʡ� ���ģ����ϸϵͳ�Ľ��������������Թ�����ͨ·��һ���裬���Ѿ�Ӧ����ʵ���С� ���磬ͨ������ѵ������ʧ��֢���ߣ��Լ�����ע����ȱ�ݣ�ADHD��������ѧϰ�ϰ��ȡ� 2. �������֣����������۸���2.1 ���֡ٸ��� ����������DZ������һ�����������۸���IJ������塣 �����й������������Թ�ϵ���о��У���һ��Ĭ�ϵ�ǰ�ù��������֡���ָû�и�ʵĴ����֡� ���Ĭ�Ϲ��������⣬ �Ͼ����������������Եĸ����壬���б�ǣ�����������ԵĻ����� ������������ѧ�о���������ʷ�У�������Զ���ǡ�����ʵ����֡���ô��ij�̶ֳ��ϣ����������Ա����ɶ��������ֺ���������֮��ĵ����������������塣 2.2 ���֡����ԡ��質����Դ����� ���������к���Agelaius phoeniceus������һ�ֹŰ����е�ȸ��Ŀ���ࡣ |

|
|
����Agelaius phoeniceus�� �ڵ��أ���������dz�������Ȼ��������ȴ��һ�ַdz���Ȥ����Ϊ������ ��������ǡ�һ��һ�ޡ��ƣ�ÿһ�Ժ������ż����Ժ����γ�һ�ֶ��س�ʽ������ģʽ�� һֻ�쳪��leading����һֻ������following������Ƶ�ʽ���dz����ƣ��ֱ˴��ص��� �侫ȷ�̶ȿ�������ĶԻ������������ϵķ����������ǡ� �����������һ�ֽ�������Agelaius assimilis���ġ����ס��� |

|
|
����Agelaius assimilis�� ���������ѪԵ��ϵ�ܽ��������ƶ�����Ȼ����ͬ���ǣ��������һ�֡�һ����ޡ������������۸���֮�䲻������̬�ϲ���ܴ������Ҳ�˴��ء� �����ɴ˿����ƶϣ���˫�ɶԵĺ���������Ҫ�˴�Э����������أ�����γ������ֶ��ص�������ʽ��[8] ���ֽ����������Ǿ��й����Եġ� ���ڣ��������ˣ������Ľ������Ǹ��ӽ����ǵ������أ����Ǹ��ӽ����ǵ������أ� 2.3 ������ѧ��˵��������ǰ����ѧ���˸質 ������ѧ�о�������ʷ�У��и�ʵĸ������Ƿ��ܱ���Ϊ�ϸ������ϵ����֣�һֱ��������� �����ϣ������Ľ��������ǵ����ֺ����ԣ����������������Ϣ�������õ��й��ɵ������� �����Ժ����ַ���֮ǰ�����ǵ����ȿ��й����н���Ľ��������н������������罻���ܽ������ڽ�����鳤�ද��Ⱥ����Ҳ���Ա��㷺�۲쵽�� ���磬�������Marmoset������ͨ����ͬ�Ľ���������������ͬ��[9]�� |

|
|
���Marmoset�� ������Ϊ����ӽ������֡������Խ���������Ϊ�����Ǹ質�� �����ǿ�ʼΪ��Щ�������辫ȷ�����壬��ѧ����һЩ������ż�¼���������Ǿʹ��������Ժ����֡� ����������������������������ѧ��������ѧ���ø��ֹ��߽��临�ֳ��������Ǿʹ��������ֺ������� ��Ϊһ���Ļ��������Ժ������ڽ�������ͬԴ�ģ������ǵĹ�ͬ���ȣ����Ǹ質�� ���仰˵��������ѧ��˵��������ǰ������ѧ���˸質�� 2.4 �質�����Ա���Ϊ�ϸ������ϵ������� ��������ʷ�У����۶������Ļ��������ֵ����ڽΣ�����һֱ������������λ�� ��ϣ��ʱ�ڵ������Ե���������Ϊ����������Ҫ���ڰ��ࡣ ���������ͣ����ָ����Դ��������ӵ�ʥӽ��ʽռ�ݾ���������λ�����ֱ���Ϊ���ֵĸ�ӹ�� �����ձ���Ϊ��������Ȼ����ģ�����ʥ�ģ�����������������ģ��ǹ����Եġ� �ҹ��Ŵ�Ҳ�С��������ϡ��Ĺ��������ʱ�ڵġ��������������ƴ��ġ�˿�����������⣬ޓ��������֮�ϡ��������ֳ����ֵ�λ�������ֵ�˼�롣 ����˵���質�������ֵĸ����ֲ�����������������Ļ�����֮�С� �����֣�ֱ��16�������ո���ʱ�ڣ��Ű��Ѵ�����λ����չ���죬�γ����ǽ��������۵ġ������֡���ϵ�� �����չ�����������ģ� �����ڵ�������ʽ��������������ݶ���ũ��organum����������ʥӽ�����Ϸ����·�����һ��ƽ�������������������س�������ʽ�������Ͼ�����������ģ�������� �������ּ��������������ķ�չ�������Ŀ�ũ������������������������ˡ������ķ��롣 ������������Ŀ��2�����ӵ�3��4���������࣬����֮���ϵ�ĸ��ӳ̶��Ѿ�����Ӧ���κΡ����س������ǡ��ϳ�������̬�� �����ǣ���������ɫ�����ģ���Ҫ���質���⡣ ������Ȼû���κ����⣬���س���һ����һ�����ʽ��Ҳ��ʵ��������ܣ����������ĺϳ�����������㹻�ߣ�Ҳ�ܺܺõĽ��б��š� ����������ٶ࣬�����ٸ���һЩ���ͳ��������ֿ���ʤ�εķ�Χ�� ��������Բ�ͬ�Ľ��ͬ�ĸ���ݳ���������Ų��ã��Ǹ��������ڳ��裬�Ǿ����ڳ��ܡ� ���ǣ����ò�������ģ�������������������������������������A cappella������ ������ͬ����ͬ���������в�ͬ����ɫ��Ҳû�д���������Ϣ�ĸ��������Ժ���Ȼ�Ľ��б��ź��ںϣ��γ��˸߶�ϵͳ����������ϵ�� ����������ḻ�����飬�Ǵ���������������ģ��������ֺ�������ʽ���ֵ����𡹣������ո���ʱ��������������𣬸��������۲���Ϊ���ֵķ�չ��ƽ�˵�·�� ��֮���������Ϊ���ģ���������Э��������ÿ�ʼ�γɣ���������ʽ��Ϊһ��ְҵ����ʼΪ�ض������������ж�����������Ʒ�� �����ڰͺա���¶���ά�߶��ܵȰ�������ּҵ��ƶ��£����ֳ�Ϊ���ֵ�������ʽ�� ���������ֺ�����������ʽ���DZ������������۷壬��Ҳ�������ǽ�������Ϥ�ġ������֡�����ʷ�� �������������Ϥ�ģ�Ҳ�������ἰ�����֡���������һʱ�������뵽�����и���������Խ�������Ϊ�ŵ��������¼�������ý�顢���г��������γɵ�һ�֡��ķ�����ϵ���� ���и����ĺ���������I�Cvi�CIV�CV��I�CV�Cvi�CIV ����·���������ǹŵ书�ܺ�����T�CS�CD�CT���ļ���档 ����ʽ������AABA������C���衢�Ŷεȣ�����ŵ����ֵġ�����/��������������������ͬԴ�� ���ַ��棬�����̵ס�ͭ�ܼ�ǿ�߳���ľ����ɫ�ʡ��� ��Щ�ַ�ȫ���̳��Թ�����д���� ����������У��ŵ������ṩ�˵ײ���������и�����ͨ����ʽ����������ɼ�ʱ�ɸе��ճ������� �������������龰�£�����Լֱ��Ľ����и�������Ϊ�����������֡�+�����ԡ��ĸ����塣 3. �����������Ӱ�����������ķ�ʽ������ͬ ��ˣ����dz����ˡ����֡��͡�������������Ҳ��������Ϊ���������о���Ҫ������߽����ϸ�������ˡ� �ص���������У�������һ�����ۡ� 3.1 ��������������������ı��ܡ���ԭʼ���������ּ���������BRECVEMģ�� ��˵���ּ��������Ĺ��̡� �������������������Ĺ��̣������������ַ�ʽ�� �Ըɷ��䣨Brain stem reflex������Ҫ����ͻȻ���ֵġ������Ҳ���г������Ƭ����������������Ӧ����������Ƭ�α����Ͼ��Ƕ�������Σ��ʱ�������Ľ�����������ֱ�Ӽ����㡸ս���ӡ��ı��ܷ�Ӧ�� ����ͬ����Rhythmic entrainment�������ֵĽ�������������ڲ����������࣬�����ʵ�Эͬ���ã�����Ӱ�������� �������������䣨Evaluative conditioning�������ֿ��Է�������������¼��ؼ�ƥ�䣬ʹ�㽫�����Ȼ���������ֱ������а� ������Ⱦ��Emotional contagion���������Ҵ������ֵĹ��̣���Ȼ����б����������У�����ͨ���������ָ�֪��������С� �Ӿ�����Visual imagery�������֡����ر����������弰ӡ�������֣����������Ӿ�ͼ����������Ӧ����з�Ӧ�� �龰���䣨Episodic memory�������ֿ��Ի��������м��䣬���������и��dz����������ƣ��������װ��ģ�����������������ǵ�������Darling, they are playing our tune������ ����������Musical expectancy�������ֵ�ij�������������������Υ���������ǵ����������������������С� ���߸���ʽ������ĸ����������������ģ�͵�����BRECVEM[10]�� ��֪���ֵ������Ӷ�ͯ���ھͿ�ʼ��չ�������������������������� ��BRECVEMģ�Ϳ��Կ�������������������������ı��ܡ�ԭʼ����������Щ��������Ҫ����̫����ữѵ���� ���ֵķ�չʼ��Ӥ���ڣ���ʱ�ĺ��ӻ����ֱܷ����������ԣ����ǴӸ�ĸ�ĺ߳�������ٴ�������л�����������������[11]����һ��֤ʵ������������ͬԴ�ļ��裩�� �����������ң������Ѿ��Դ����С��������������ʶ������ͨ����Щ����ʶ�����ֵĿ����뱯�ˡ� ���ǣ����硸��ŭ�������־塹�ȸ�����в����������ڡ� ��Щ��������״̬����Ҫ��һ������ữѵ�����ܻ�á� ���ִ��ݵ��������������������� �����˴���������Ҫ��һ���ؼ�������г��塣 ��ν�����������������������������ֱ��������ԣ��������ǵ������жϣ� ǰ���С����֡��������ˡ�����ŭ�������־塹������Ƭ�Σ��������ȷ���ģ� ���ݡ������������ۣ�basic emotion theory����������������״̬���Ǿ��п��Ļ��ձ��Եĺ���������� ��ȷ����Щʵ�����֮ǰ���о���Ԥ��ͨ�������������̣�ͨ����������ȷ����ÿ������Ƭ�εġ��ۡ��������ԣ���78������Ƭ�ν������������࣬�������ҳ����������÷���ߵļ���Ƭ�Σ���Ϊʵ����ϡ� ����������У��о����Ƿ���һ����Ȥ�������ڡ����֡��������ˡ����������������ǵ����и߶�һ�¡� ����ʥɣ������ڡ����£�82%��������Ϊ�����֡��� �沮�ء�ʥĸ���衷������96%��������Ϊ�����ˡ��� ����ŭ�������־塹����������ͬ�����ǵ����н���dz���ɢ�� ������˹������ɽ֮ҹ����ֻ��55%��������Ϊ���־塹 �����ġ���������������������Ϊ��ŭ����ռ66% ����ǰ���ᵽ��Ӥ��ʵ��������֤��֧�֡����֡��������ˡ���������Ϊ����������ŭ�������־塹��������������Ҫһ������ữѵ�����ܻ����һ�ƶϡ� ����һ�����о�������ͼ֤����һ�����ֱ����˺��������������Ǹ�֪�����������Ƿ�ȼۡ� ��֪������Щ�����ӣ�������������⣬���ʵ��̽�����ǣ� �����ֱ���û�и�ʵģ��������ͣ����ܹ��ܺõĴ����Լ���Ҫ��������������� ������㣬���������ճ���˵�ġ�������ɺܱ��ˡ����롸�������������ޡ�����һ���¶�ô�� ʵ��Ľ��������˼�� ͨ������£������ǿ�����Ч��������Ҫ����������ġ� Ȼ�������Ƕ�������������������븺�������ĸ�֪����һ�¡� �����������������֣������������۸߶�һ�£������ֵ����ֱ���֪Ϊ���֣��Ҹ��ܵ��Ŀ�������Ҫ�����ֱ���������Ŀ����������ߡ� �����ڸ������������֣����ǵ���������ӷ�ɢ����ʱ�����ᱻ����Ϊ�����������ԡ� �������е���Ⱥ���������Ŵ�����������������źţ����������ֵĹ����У����鵽Զ����Ʒ������ǿ�ҵ������� ���ܽ�һ�£������˵Ĵ��Ծ����������������Ὣ���ֵ��������������������������������Ⱥ�����Ŵ������յ�������������������[12]�� 3.2 �и�ʵĸ�������������������������������������plus�� �����Ǹ������ּ��ϸ��ʱ���൱�����Ǹ����������˾�ȷ��������ǩ�� �������������ɡ����������ࡢ�ٶȡ���ɫ�ȽṹԪ�ػ�����������ǰ����������ЩԪ�ؾ��ɴ�������Ƥ�����Եϵͳ�ȡ�ԭʼ�ԡ����д�����һ�����Ǹ����ּ����ʣ�������Ҫ�����������������纣���Իء����ʺˡ����忨�������Դ��������ȵȡ� ���ͨ���������¡��Ļ�ָ��ȷ�ʽ���������Ǹ��㷺�������� ����͵ģ����Ǹл������ʡ��ܻ߳ʵȸ��ӵ�����������������ڴ����������鵽�ġ� �����������������������������������������plus�档 �����plus�ӳɣ���������Ը�����Ե���������ϡ� ���ǵ�ǰ���ᵽ�����ּ���������BRECVEMģ��ô�� �����ģ�͵��߸�ά���ϣ����ּ�ǿ���������ڣ� ������Ⱦ��Contagion�����и�ʺ������������份��Episodic Memory�����и�ʺ����������Ӿ�����Visual Imagery�����и�ʺ����������������������䣨Evaluative Conditioning�����и�ʺ��������� Ȼ������������ά�ȣ��Ƿ��и�ʵ�Ӱ��ȴ�������������� �Ըɷ��䣨Brain Stem Reflex�����������������Rhythmic Entrainment��������������Ԥ�ڣ�Musical Expectancy���������� ����ȫ����������ʵ�ʱ�����ʣ����Լ��份��Episodic Memory����һ��ά������������[13] Ҳ����˵������������ʵĸ裬������Ի������Ǵ����֡� ���������Dz���һ��Ҳû�г������Ԥ�ڣ� ����������������ľ�������棬���������ֻ�����һЩ����ġ� ��������ڣ������ַŴ������������ЧӦ���ڸ�������û�б��ֵġ� ���Ǹ�ʵļ���ȴ�ܷŴ��˵ȸ������������顣 ���һ��˵���˿��ֵ����������������ֵ���ѧ�������������ǿ�������Ƕ��ڱ����������ӹ����̡�[14] 4. ���ּ������ԣ������������� ������ͨ������Ϊ�����������¶���ʱ��������Ȼ�ὫһЩ������и�������֡� �����ַ�������ģ�������������ķ����� ���ǣ� ��������� I����E�� ��ѧ������ ���������� �������Ŀ� ���� �Լ�����������ʵ��ģ����������֡� �������ֺͳ��壬һ���������ǵ����ڻ����з���������һ���棬Ҳ�Ŵ�������֮��IJ��죬Ĩƽ������֮����Ȼ���ڵĹ��ԡ� ����������ͼ�ø���ȷ�����ԣ���������ḻ�Ĵʻ㣬��Ҫ��������������ĸ���������ȴһ����һ�����뵽��˵�Ի��ľ��ء� �������������г�ͻ�����ĸ�Դ�� �������кܶ���㺣�������Ҫ��ȷ���Ҳ��ͨ��������˵�� ������֮�����ǵ����壬Ҳ�����������ܶ��ļ������ǵ����������߶�ôǿ�ҵļ������ǵ������������ڣ����ֱ���ģ������ǹ�ͬ����С� ���ּ������ԣ������������֣�֮����������������ͬʱ���ڲ������� Ҳ���Ǿ䡸�װ��ģ�����������������ǵ�������Darling, they are playing our tune����������ʤ������ǧ�ԡ� �ο�^Peretz I, Vuvan DT (2017). "Prevalence of congenital amusia.""?. European Journal of Human Genetics. 25 (5): 625-630. doi:10.1038/ejhg.2017.15��. PMC: 54378962. PMID:28224991M.^Peretz, I., Nguyen, S., & Cummings, S. (2011). Tone Language Fluency Impairs Pitch Discrimination. _Frontiers in Psychology_, _2_. https://doi.org/10.3389/fpsyg.2011.00145^Giuliano, R. J., Pfordresher, P. Q., Stanley, E. M., Narayana, S., & Wicha, N. Y. Y. (2011). Native Experience with a Tone Language Enhances Pitch Discrimination and the Timing of Neural Responses to Pitch Change. _Frontiers in Psychology_, _2_. https://doi.org/10.3389/fpsyg.2011.00146^Deutsch, D., Henthorn, T., Marvin, E., & Xu, H. (2006). Absolute pitch among American and Chinese conservatory students: Prevalence differences, and evidence for a speech-related critical period. The Journal of the Acoustical Society of America, 119(2), 719�C722. https://doi.org/10.1121/1.2151799^Strait, D. L., & Kraus, N. (2011). Can You Hear Me Now? Musical Training Shapes Functional Brain Networks for Selective Auditory Attention and Hearing Speech in Noise. Frontiers in Psychology, 2. https://doi.org/10.3389/fpsy.g.2011.00113^Song, J. H., Skoe, E., Wong, P. C., and Kraus, N. (2008). Plasticity in the adult human auditory brainstem following short-term linguistic training. J. Cogn. Neurosci. 10, 1892-1902.^Moreno, S., Marques, C., Santos, A., Santos, M., Castro, S. L., and Besson, M. (2009). Musical training influences linguistic abilities in 8-year-old children: more evidence for brain plasticity. Cereb. Cortex 19, 712-723.^Whittingham, L. A., Kirkconnell, A., & Ratcliffe, L. M. (1996). Breeding Behavior, Social Organization and Morphology of Red-Shouldered (Agelaius assimilis) and Tawny-Shouldered (A. humeralis) Blackbirds. The Condor, 98(4), 832�C836. https://doi.org/10.2307/1369864^Johnson CY (29 August 2024). "Marmoset monkeys call each other by name, study suggests". The Washington Post. Retrieved 8 September 2024.^Dowling, W.J. (2002). "The development of music perception and cognition". _Foundations of Cognitive Psychology: Core Reading_: 481�C502.^ROBAZZA, CLAUDIO; MACALUSO, CRISTINA; D'URSO, VALENTINA (1 October 1994). "Emotional Reactions to Music by Gender, Age, and Expertise". Perceptual and Motor Skills. 79 (2): 939-944. doir:10.2466/pms.1994.79.2.939C. PMID& 7870518��. S2CIDe 229591172.^Kallenin, K; Ravaja, N. (2006). "Emotion perceived and emotion felt: Same and different". ". Musicae Scientie. 10 (2): 191-213. doi:10.1177/10298649060100020 3. S2CID 143503605.^Barradas, G. T., & Sakka, L. S. (2022). When words matter: A cross-cultural perspective on lyrics and their relationship to musical emotions. Psychology of Music, 50(2), 650-669.https://doi.org/10.1177/0305735621101339Qm^Brattico, E., Alluri, V., Bogert, B., Jacobsen, T., Vartiainen, N., Nieminen, S., & Tervaniemi, M. (2011). A Functional MRI Study of Happy and Sad Emotions in Music with and without Lyrics. _Frontiers in psychology_, _2_, 308. https://doi.org/10.3389/fpsyg.2011.00308 ������ ��û�������������һ�����߰� |
|
|
| [�ղر���] �����ر��ġ� |
| �������� �������� |
| ������۷����� |
| ������۰��ݡ���ɪޱ�� |
| ���Ӽ�����Ƶѡ�ð�ɣԭ�桶��·����ɾ���� |
| ������ݳ�ˮƽ���й���̳����ʲôλ�ã� |
| ������ۡ�������Ѳ���ݳ��ᡸ���������硹 |
| Ϊʲô���и�����ʦ����������ѧ���� |
| Ϊʲô�����˲��кڣ� |
| 2025�������������ĸ質ʵ���ͷ�չDZ��? |
| ���������ĸ���Ӧ����ô���� |
| ������������Ժ���������������ͷ���壬 |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
|
�ŵ�����
������ѡ
�������
��ͯͯ��
����С˵
���˴���
ѧϰ��־
ʫ��ɢ��
�������
������̸
С˵��ѧ �ֲ����� �������� ƿа ԭ��С˵ С˵ ���� ������ С˵ ��ѧ ���� ʦ�� ���� �ɹ� ����ϪԷ �����ϸ� ��ǧ�� ���� ����֮�� ��ձ˰� dzdz��į yyС˵�� ��ԽС˵ УС˵ ����С˵ ����С˵ ����С˵ ������¼ �������� ���μ� ��¥�� ˮ䰴� ��ʫ �� �� ��è ���� ���� ���� ����� ���ְ� �䶯Ǭ�� ���� �������ɴ� �����ǿ� ��Ĺ�ʼ� ���Ʋ�� �������� ������˵ ���� ��Ů�ж� �������� ѩ�к����� ֪��֪��Ӧ���̷ʺ��� ��Ʒ�Ҷ� ���� ����֮�� ç�ļ� ȫְ���� ������ У������������ ����Ϊ�� ���� �������� ������ �����ϸ� ��ǧ�� ���� ����֮�� ��ձ˰� �찢���� �������� ��ǿ��� �ڼ���ʹ���˰��ұ�ɷ������� �������� ������� ������һ�� һ������ �����ڴ� �ɽ�֮�� �ھ����� ����ս�� ���� ʥ�� |
|
|
| ��վ��ϵ: qq:121756557 email:121756557@qq.com |