| |
|
|
|
| 阅读网 -> 人物音乐 -> deepseek r1算不算是agi的雏形? -> 正文阅读 |
|
|
[人物音乐]deepseek r1算不算是agi的雏形? |
| [收藏本文] 【下载本文】 |
|
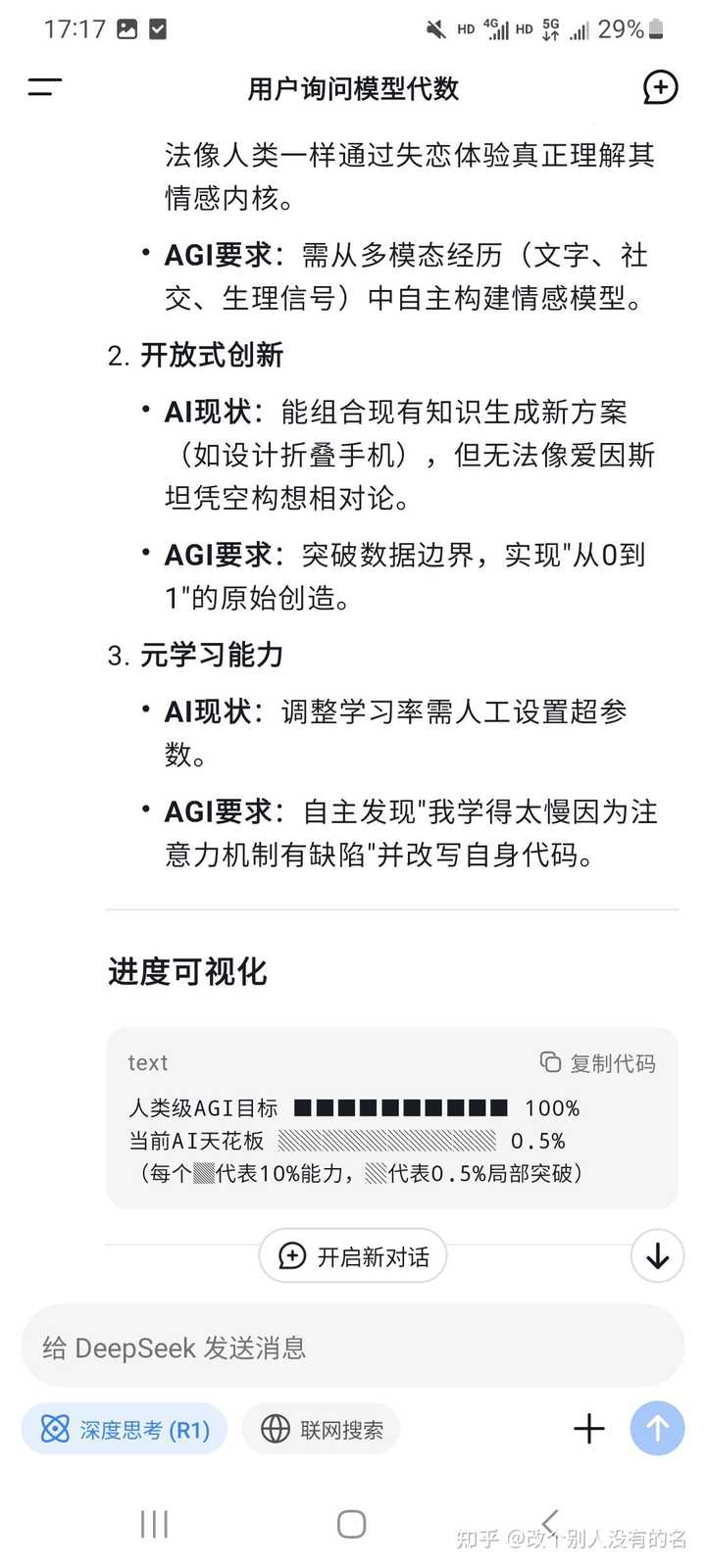
deepseek在没有添加CoT的情况下可以自行领悟它也有自主学习的能力,并且在训练过程中完全没有人去进行监督。 听说deepseek还有一个比较玄乎… |
|
多谢您的邀请。 ①我把AGI当做社会全自动化程度指数,比如AGI 0.3,那么说明社会产业的30%已经完成了全自动化。我觉得现在AGI还在0.05-0.1之间,而且跟大语言模型关系还不大。 ②你把接近人类当做AGI的标准,这就很难说了。你可能觉得R1快接近你了,但在我看来,R1已经远远远超过了我。 如果我来做一个Chatbot,一问三不知,回复速度慢,还各种脾气,用户会气得杀心骤起,拿起键盘砸穿显示器。――那么,在我看来,R1算不算ASI? 所以,你这个AGI定义是非常“垃圾”的定义。 我们来重新定义一下R1/o1的智能水平: ①它是一个运行语言模型内部的“Reasoning Agent” ②R1有自主性,有能动性,有任务目标感,这是它和传统LLM不同的地方。 传统LLM是把你的问题映射到SFT数据集上,对比差异性,然后进行概率输出,不会有任何主动性。 ③R1会自我探索,它会思考用户想要什么(AI对齐,很爽),它会自我纠错,它会自我斟酌。 这是它作为高级Agent的特性。 ④它作为一个运行在语言空间里的高级Agent,它可以处理“已语言化”的任务――比如搜索,数学,代码,写作,角色扮演。 ――如果你觉得我说得太狭隘,那么请你尝试想出一个“非语言化”的任务,让R1去做。 ⑤语言,是Agents(包括人类)对世界的一种“符号压缩算法”,语言是离散的符号,里面已经去掉了极大量的世界细节,如果要让R1执行世界任务,那么需要进行大剂量的强化学习,来填补语言间的离散空间。 所以R1的智能仍然被锁在了语言空间里。它没有世界通用性――所以,仅按照AGI字面意思“通用人工智能”,R1也不是AGI,只是一块必要的跳板,我们还需要很多跳板(这画面看起来真累人,跳死算了),包括肢体直觉模拟,三维场景感知,多觉联调……等等。 |
|
对r1的评价: 基础智能(实时识别的单位长度文本因果信息密度)相当于智商90-100的人类。 简单来说,对于完全未知的任务,在相同思考量下,r1的表现不会大于智商90-100的人类,这是r1泛化能力的上限。 实际上,“智能密度”(基础智能)才是衡量智能水平的正确指标,而不是“性能表现”,因为对低智能的模型/人类来说,性能表现可以靠“经验”弥补。在基础智能不成为因果拆分瓶颈的前提下,提高思考量稀释输入信息的因果信息密度,也可以提高正确率/性能表现(所以人类的考试、智商测试必须限时)。 同样对于r1,由于RL过程让模型获得了远超正常人类掌握数量的“经验”,在训练数据范围内,r1的表现会显著高于同等智能水平的人类。结合比输出文本长得多的思考文本量,很容易让使用者产生错觉,认为r1非常聪明。 但说r1是AGI是无稽之谈,一切能力表现的根源,仍然只有90-100智商的人类水平(然而这个表现放在几年前,也是天方夜谭)。 另一方面来说,r1的基础智能比v3有显著提升。大致估算,不考虑潜在的异常涌现,还需要至少两次v3到r1级别的提升,模型的基础智能才能接近高智商人类水平,这时应该差不多可以算是AGI的雏形了。 假设不进行任何改进,不出现任何涌现,到o4训练结束才有可能出现AGI雏形。并且每一代升级,都需要按对数关系提高计算量,算力缺口依然很大,所以OpenAI这两天还在叫嚷算力重要。 问题在于,有可能进行改进,也有可能出现涌现。 首先需要转变认识,将研究的第一优先从增加正确率转移到增加智能密度上。单就这一个转变就有可能将抵达AGI所需的计算量减少量级。 因为正确率越高,犯错越少,犯错越少反馈越少,所以需要按照对数关系增加计算量、数据量才能持续提高正确率。 然而,如果以智能密度为优化目标,不改变正确率,靠压缩模型的输出信息量提高智能密度,则模型的改进速度不会因智能提高而减速,可以估算出理想情况下抵达AGI仅需r1后训练的3倍左右计算量(考虑压缩结束后的思维链延长过程)。 注意,上述计算量实现的前提,是压缩智能时,单次反馈过程的基础智能增加量不小于思维链自由延长时,这一点比较乐观,但也存在由于非因果推理(背答案/背过程)增长,导致基础智能增长减缓的可能。同时,也不考虑思维链长度瓶颈导致无法压缩智能的可能性。 按照这个计算量估算,不考虑方法试错和数据准备的耗时(假设有高人已经提前把这些准备好),以现有条件为基础(以开源r1为基础,各家算力不增加),AGI雏形最早会在6个月后出现。 但还有一个涌现问题。 显然,目前RL时的思维链延长现象是不可能无限继续下去的(因为题目的难度是有限的)。 在训练程度超过某一位置后,自由释放模型的长度反馈限制,模型可能会由自主延长思维链转变为自主缩短思维链。 此时基础智能可能会随着RL快速增长(涌现)。 这个涌现可能发生在智能压缩末期,但会显著加快涌现位置后的训练速度(相对于思维链长度无约束时)。 这样估算,抵达AGI雏形的耗时可能缩短约1个月。 整理可知: 理想情况下,AGI(雏形)的抵达时间是2025年6月(假设改进措施全部有效,算力增加量抵消了试错消耗量)。 悲观情况下(方法改进全部无效,无涌现,但可用算力比当前提高10倍),AGI雏形抵达还需20个月,抵达时间是2026年9月。 如果算力极为充沛(比例相当于xAI的10万 H100 vs v3的2000 H800),进度可大大提前,答主认为OpenAI就有离谱的算力,所以OpenAI有可能靠大力出奇迹在2025年6月-7月附近o4训练结束时抵达AGI雏形。 抵达AGI雏形意味着AI研究工作基本结束,实际上,甚至不存在让AI自我改进的必要,只要沿着当前路线继续增加计算量,模型的智能密度也会达到前所未有的程度(全由“显然”、“注意到”构成的思维链你受得了吗)。AGI雏形出现后,ASI将很快抵达,留给社会的缓冲时间很短。 PS: 现在距离2025年年中不足半年,在这里贴这种容易打脸的预测相当危险 |
|
差远了: DeepSeek获得了空前的成功,那他有没有什么不足之处?18 赞同 ・ 0 评论回答 我之前所指出的“业界误判”,deepseek 并没有逃脱: AGI 的发展目前完全没有理论支持,一大帮人居然还以为一味扩大 LLM 规模就能实现通用人工智能。 |
|
AGI的重点在于“通用”,不能只局限在文字任务,能算AGI的必须是个多模态模型,至少要有语言和视频两个模态,这样像自动驾驶、自动打游戏,图文混排图文并茂等任务才有可能,否则没有视觉能力,写个影评都不能自己看电影。AGI必须有持续学习的能力,不能像现在这样分为训练阶段和应用阶段,在应用阶段无论用户用AI写了多少文章AI的写作水平也不会提高,而是被锁死在训练完成那一刻。AGI应该像人类一样训练和应用是一体的,可以不断从应用中学习,正所谓“熟能生巧”,AI应该在和用户对话中、在完成用户任务的过程中持续学习,要在发布后还能学会新的技能,让普通用户也能教会AI新的东西,比如下棋。无论如何现在的llm离AGI还差得非常远,一些AGI的关键特性还没有出现。 |
|
DeepSeek这个强化学习路线有实现AGI的潜力。可以从数据和RL环境两个角度来看 RL的训练过程,实际上创造了人类数据之外的新数据,至少CoT部分是模型探索获得的,这个数据是有价值的(对结果的Reward)。模型在越来越多的RL环境中取得成功,意味着在越来越多的环境中达到甚至超越人类水平。枚举这个环境,直到再也找不到人类的优势,则AGI即成。 当然,实现起来还是有很多困难的,可能会撞到其它瓶颈。比如,你很难找到一个自动出题机,让模型不断RL进阶,尤其是那些困难的问题。 个人观点,拓展能力比增加难度要更重要。应该通过RL扩展AI使用各种工具的能力(比如搜索,编写程序等等),AI应该具备总结和清理上下文的能力(可以提炼关键步骤和结论,把无关的内容删除。草稿纸写不下的时候,可以新开一张) |
|
科学没有政治立场,正如同语言模型并非正确的认知架构,错误的范式就是错误的,不会因为政治立场是中国还是美国就会突然让模型拥有认知能力 而且题目所说的r1有自主学习能力是完全错误的,目前的深度学习并没有实现突触可塑性,模型的参数,权重,步长都是完全静止的 |
|
oai都没敢说o3模型火力全开能到agi的雏形,结果ds就成为agi的雏形了 ,而且看你的提问,好像chatgpt3.5时代的人 |
|
问一下神奇deepseek不就知道了。 |

|
|
|

|
|
|
|
|
|
|
不算,人类科技离agi的距离比可控核聚变还要远得多 |
|
不算,具有持续学习才是。现在所有的模型,有一个算一个,都不具备。 |
|
现在不算AGI,但这个引入了强化学习(更加强度这方面),类似当年围棋AI一样,引入强化学习后,一举超过了人类的围棋水平,未来可能会很大的进步空间。 以前主要靠人类的数据,后面理论上可以使用AI来生成多数数据,这样在强化学习加持下,会出现巨大的进步。 现在只是刚开始,后面估计进步的速度和空间会更大。 估计未来在很多专业领域会超过人类的水平,特别是综合运用知识上。 围棋AI并不是算出妙招一招把你下死(至今没能算出最优解),而每一步都能保持很高的赢概率,这样只要你有一招失误了,后面就输了。你可能有几招比它下得好,但无法持续输出高水平,而围棋AI可以持续输出高水平,就等你失误,就算你不失误最多和它打平手(任一方也赢不了多少子)。 在强化学习引入围棋后,围棋AI A对战围棋AI B,这样不断生成棋谱数据,产生大量高质量数据,再训练后,围棋的AI水平一下子从五段干到了九段以上。 所以未来可以预期大模型的智能程度会有巨大的进步,加上节省算力,应用会更加广泛。 |
|
如果以后科研是AI主导创新人类打下手的话,AGI的存在似乎不是那么重要 |
|
他的吹牛 吹的我 自己的大脑快烧完了 但又是畅快的 被他搞得糊里糊涂得 直呼我草 才是他的真正的成功 |
|
deepseekr1当然不算,仅仅是个LLM而已。 |
|
|
| [收藏本文] 【下载本文】 |
| 人物音乐 最新文章 |
| 如何评价范进? |
| 如何评价安妮・海瑟薇? |
| 央视纪念视频选用巴桑原版《天路》,删掉韩 |
| 韩红的演唱水平在中国乐坛处于什么位置? |
| 如何评价《鸣潮》巡回演唱会「致予新世界」 |
| 为什么会有钢琴老师讲不带成人学生? |
| 为什么孙燕姿不招黑? |
| 2025年如何评价周深的歌唱实力和发展潜力? |
| 周林王陶四个人应该怎么排序? |
| 如果汪苏泷,许嵩和徐良,网络三巨头合体, |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
|
古典名著
名著精选
外国名著
儿童童话
武侠小说
名人传记
学习励志
诗词散文
经典故事
其它杂谈
小说文学 恐怖推理 感情生活 瓶邪 原创小说 小说 故事 鬼故事 微小说 文学 耽美 师生 内向 成功 潇湘溪苑 旧巷笙歌 花千骨 剑来 万相之王 深空彼岸 浅浅寂寞 yy小说吧 穿越小说 校园小说 武侠小说 言情小说 玄幻小说 经典语录 三国演义 西游记 红楼梦 水浒传 古诗 易经 后宫 鼠猫 美文 坏蛋 对联 读后感 文字吧 武动乾坤 遮天 凡人修仙传 吞噬星空 盗墓笔记 斗破苍穹 绝世唐门 龙王传说 诛仙 庶女有毒 哈利波特 雪中悍刀行 知否知否应是绿肥红瘦 极品家丁 龙族 玄界之门 莽荒纪 全职高手 心理罪 校花的贴身高手 美人为馅 三体 我欲封天 少年王 旧巷笙歌 花千骨 剑来 万相之王 深空彼岸 天阿降临 重生唐三 最强狂兵 邻家天使大人把我变成废人这事 顶级弃少 大奉打更人 剑道第一仙 一剑独尊 剑仙在此 渡劫之王 第九特区 不败战神 星门 圣墟 |
|
|
| 网站联系: qq:121756557 email:121756557@qq.com |