| |
|
|
|
| 阅读网 -> 人物音乐 -> ClickHouse 到底有多神? -> 正文阅读 |
|
|
[人物音乐]ClickHouse 到底有多神? |
| [收藏本文] 【下载本文】 |
|
ClickHouse 到底有多神? |
|
偶然刷到这个问题,感觉还挺有意思的…… 不知道从啥时候起居然已经有人开始用“神”来形容 ClickHouse 了,那作为曾经做过 ClickHouse 二次开发的我岂不是神的使徒?(开个玩笑) 首先,ClickHouse 作为一个开源的数据仓库产品,不能说是最好的,但绝对可以称得上是独具特色的。当大家都在复用 Hadoop 各种组件构建自己的数据仓库技术栈时,ClickHouse 直接站在人群中央大声宣称:“在座的各位都是垃圾,用我就够了。” 虽然说话有点冲,但它确实有充分的理由让用户选择它――除了 Zookeeper 不依赖任何 Hadoop 组件,还拥有卓越的性能和丰富的函数库。 在大家苦苦等待 Hive 跑完第一条查询时,ClickHouse 往往已经完成了所有报表的计算(如果使用得当的话)。在最优场景下,ClickHouse 相对于 Hive 的性能提升甚至可以达到夸张的几十倍。正是这种极高的上限使得 ClickHouse 吸引了全世界的目光。 之所以能达到如此的高性能,是因为 ClickHouse 背后的团队对于性能有一种执念,他们为了追求极致付出了非常多的努力。 表面上看 ClickHouse 使用了大量的前沿技术,比如框架层面的向量化执行引擎(Vectorization)、列式存储引擎(Columnar Storage),以及针对各种场景优化的数据结构和算法。但事实上这些并不是什么火星科技,在商业数仓领域它们早就被用烂了,例如列存引擎的开创者 Vertica 和向量化执行的开创者 Vectorwise。 所有涉及的技术都有丰富的论文资料和成熟的实践方式,任何一个产品理论上都有机会利用这些技术,结果放眼整个开源界偏偏只有 ClickHouse 脱颖而出。ClickHouse 背后的团队并非什么专业的商业数仓供应商,只是俄罗斯“百度”―― Yandex 的员工;他们不需要做出什么行业前沿的产品,只需要满足自家广告业务的数据分析需求;核心负责人 Alexey Milovidov 也不是计算机科班出身的工程师,而是莫斯科国立大学的数学博士。然而就是在这样的背景下,他们做出了开源界性能最优异的数仓软件。 顺便提一嘴,Alexey Milovidov 是我最敬佩的工程师之一。这么多年来他始终在一线写代码,并且对系统的很多细节都了如指掌,绝非常人所能。 |

|
|
我在 ClickHouse 的 Telegram 群向 Alexey 请教问题 当别的产品图省事用 Java 开发时,他们为了性能选择了 C++;当别的产品摆烂只实现基础功能时,他们实现之后还在做各种性能优化;当列存和向量化二选一就能吊打其他产品时,他们选择了全都要。 让我印象非常深刻的是 ClickHouse 对于 Decimal 数据类型的实现。对于一般的数据库,比如 MySQL 之类的,Decimal 都会实现为一个变长的类型以方便在不同的 scale 之间进行转换和计算。ClickHouse 为了追求性能,将 Decimal 类型的底层使用定长的整数类型来表示,每个 scale 都会有一个最邻近的整数类型。因此在 ClickHouse 的代码中单单一个 Decimal 类型就对应了 Decimal32, Decimal64, Decimal128, Decimal256 等一系列物理类型,同时针对每种类型还有对应的 function 特化,让人看一眼就头大。相比起存储的 I/O 开销,这种类型特化带来的性能提升可以说是微不足道,同时还会增加代码的复杂度,但这仍然没能妨碍 ClickHouse 做出这种设计。 也正是这份不求回报的坚持让 ClickHouse 变得独树一帜,成为了开源软件的新标杆。成就它的不是多么“神”的技术,而是扎实的 C++ 编程基础和追求极致的态度。 然而在强大的性能背后的并不是一个美妙的世界,如我开篇所说的,ClickHouse 很难说的上是最好的产品。 虽然在性能上拥有极高的上限,但是 ClickHouse 的使用体验几乎可以用“灾难”来形容。部署一个单机的 ClickHouse 很简单,简单跑些查询也很简单,一到上生产就要命了。数据分区、数据备份、数据恢复、集群扩容、数据导入/导出、版本升级等等等等,统统都是手动挡,并且缺少文档资料。 正当你焦头烂额地研究如何升级集群时,前方突然传来捷报,一个用户的一条查询请求直接打爆了正在写入数据的集群。现在数据只写入了一部分,查询报表也出不来了,一群用户正围着你给你讲他们有多急,美好的一天就这样结束了。 造就这种结果的是 ClickHouse 团队的“傲慢”。作为自己领域的佼佼者,他们对于用户也有很高的要求。相比一个成熟的数仓软件,ClickHouse 更像是一个高性能的 library,用户需要自己做很多工作才能让它真正地跑起来。ClickHouse 虽然提供了 SQL API,但是不了解其内部设计与实现也不能跑出理想的性能。 比起面向容错设计的 Hive,ClickHouse 给不了用户任何的安心感。Hive 虽然慢,但是它总是能跑完发送给它的查询;ClickHouse 虽然快,但他就像一辆大马力赛车,使用不当的话起步就会熄火。 默认情况下,ClickHouse 会尝试吃光所有的资源来完成每一条查询,因此当面临并发或者复杂查询时,进程因为使用资源过度而被 OOM killer 干掉是家常便饭。为了解决这种问题,ClickHouse 的做法是提供了大量的配置参数和开关,用来精细控制查询的各个环节。这些参数大到执行并行度,小到 hash table 的内存分配算法阈值,用户只有结合对系统的理解才能调出适合自己的参数(而且大概率只针对特定查询)。 到这里普通用户已经晕了,但是这还没完。ClickHouse 上游版本的更新非常勤快,虽然团队人数不多,但是几乎每天都会有 Pull Request 被合并。而这些改动中,除了 bug 修复,最多的内容就是各种性能优化,这其中会涉及到新 feature 带来的最佳实践的改变以及配置参数的 breaking change。使用体验优化的部分不能说没有,但是确实不怎么多。 这带来的问题是,用户如果想要跟上上游的更新的话,就必须得积极的关注 ClickHouse 的社区动态,同时随时制订自己的升级计划。一旦没跟上节奏,很可能就会因为 breaking change 等因素再也无法平滑更新。这也是为什么那么多大公司的 ClickHouse 集群都锁定在了某个特定版本,只能看着上游的新 feature 流口水。 快速迭代反映出了 ClickHouse 团队的“猛糙快”特质(很符合国人对于俄罗斯“战斗民族”的印象),他们的开发速度非常之快,突出一个“猛”;代码虽然设计上不够完善,但是能跑,突出一个“糙”;开发的功能基本都是为性能服务的,突出一个“快”。对于来自外部的贡献他们也毫不排斥,只要能过测试,有提升,PR 就能合进去。 然而这种“猛糙快”的特质也为 ClickHouse 带来了危机。 在我刚接触 ClickHouse 内核代码的时候,我是一脸懵比。学过数据库的朋友们都知道,一个关系型数据库一般会分成多个模块,主要有解析器(Parser)、优化器(Planner/Optimizer)和执行器(Executor)。在这中间 SQL 会被转化成各种中间表示(IR),从抽象语法树(AST)到逻辑计划(Logical Plan)再到物理计划,以便进行各种查询优化和代码扩展。然而在 ClickHouse 中这种概念是一点也找不到。 在 ClickHouse 中,SQL 被 parse 成 AST 之后就会直接交由一个叫做 Interpreter 的模块直接执行。没有常见的 Plan IR,各种语义分析和查询优化散布在系统的各个角落。你甚至能看到 AST 被传递到 Storage 模块用于对 ClickHouse 的存储引擎 MergeTree 进行 Sparse Index 的过滤。 整个系统中充斥着各种令人费解的地方,比如不支持关联子查询(Correlated Subquery),不支持 CTE(Common Table Expression),仅使用一个 String 来作为 column 的标识(DataSchema),使用类似 Monad 的 Nullable(T) 表示 NULL 的类型却不允许嵌套的 Nullable,没有 Join reorder 优化,分布式查询仅支持简单的 Broadcast Join 和 Aggregate,不支持事务也没有任何并发控制机制。 这其中最让我感到费解的点在于,ClickHouse 缺失的绝大多数功能实现起来都并不困难,设计多种 IR 也是很自然的选择,以这个团队的实力来说解决这些问题绝对不是难事。但是事实就是在很长的一段时间内,这些问题都没有被改善。他们甚至有精力重写整个并行执行框架,从 DataStream 切换到 Processor。 因为这些设计问题,ClickHouse 在面对复杂查询时十分无力。它甚至无法跑通分析领域最权威的 TPC-H 和 TPC-DS 基准测试,只能在自己的舒适区内设计一个只有单表聚合查询的 hits 基准测试来秀肌肉。 https://benchmark.clickhouse.com/?benchmark.clickhouse.com/ 总而言之,ClickHouse 有自己的舒适区,但是想要驾驭它必须付出汗水,属于穷人的法拉利,富人的拖拉机。对于有一定研发实力又不愿意采购商业数仓软件的用户来说,ClickHouse 是一个相当不错的选择;对于没有研发实力,但是财力雄厚的用户来说,ClickHouse 就是鸡肋。 客观上来讲,ClickHouse 是一个优秀的 C++ 项目,一个无情的单表分析机器,但它绝对不是“神”。这个世界上是没有“神”的,只有以“神”度己的“人”。 ClickHouse 就像一个家世不显赫的普通人,有理想和追求,付出了努力,同时取得了一定的成就。然而和大多数人一样,它也有自己的执念,而正是这些执念拖慢了它向神前进的脚步。 从我个人角度来讲,ClickHouse 很难称得上是一个好的产品,然而它确实对我以及我周围的人产生了深远的影响。我的职业生涯开始于 ClickHouse,从它的身上我学到了不少东西,也吸取了不少的教训。 我无法给出全面客观的评价,但比起成为“神”,也许被人们记住是更高的成就,而 ClickHouse 值得被人们记住。 |
|
利益相关:在外企用过 Vertica,前同事在做 StarRocks,自己用 CrateDB 做数据分析 ClickHouse 一点也不神,它只是个穷人版本的 Vertica,你要做过它的运维就知道多穷了。 它只是个把向量化做到极致的列存储引擎,它甚至不是一个完整的 MPP 数据仓库[1]。 我没看过 ClickHouse 的细节,因为它是个纯工程驱动的东西,不像 Vertica 本质上是个理论研究的成果。有兴趣可以读 Stonebreaker 的 paper,Projection 才是这里面最优雅的部分[2]。我没时间读 ClickHouse 的代码,如果有 Paper 请指条路――<划掉>但是我估计这货大概率没有 Projection</划掉>[3]。 我以前的同事在 StarRocks搞向量化引擎。我相信不管是从易用性和性能都能做得比 ClickHouse 好,主要是没有历史包袱。我朋友圈里面也能看到国内的很多大厂在 ClickHouse 上魔改,我也能理解,就跟中国的早期军工差不多―― |

|
|
近看五对轮 只是再怎么魔改,八爷也没办法变成 J20 啊。 |

|
|
记得装四节南孚电池 BTW:有很多人不知道 Stonebraker 多么逆天,此人几乎把所有可能的数据库范式都折腾了一遍,而且每次做出来的东西都是突破性的,基本上做到了当时的极致。搞互联网的码工被 MySQL PTSD 太久,都不知道 PostgreSQL 生命力有多么顽强。有兴趣还是读读 Stonebraker 讲述自己的微小贡献吧―― https://thenewstack.io/dr-michael-stonebraker-a-short-history-of-database-systems/?thenewstack.io/dr-michael-stonebraker-a-short-history-of-database-systems/ 参考^它甚至不是一个真正意义上的分布式系统。^https://arxiv.org/abs/1208.4173^居然支持了,毛子也不容易啊。 |
|
ClickHouse(简称 CH)是最近很受关注的开源分析数据库,据说挺神的,做 OLAP 计算很快。很多被性能问题折磨的用户都有兴趣尝试一下。 CH 到底是不是真有那么神呢?我们做一些对比测试来看看。 这里用 CH、Oracle(简称 Ora)和开源的集算器 SPL 一起做对比测试,测试基准是国际广泛认可的 TPC-H,针对 8 张表,完成 22 条 SQL 语句定义的计算需求(Q1 到 Q22)。在相同的软硬件环境下,比较 CH、Ora 和 SPL 完成计算需要的时间。 测试发现这么几个现象。 一、CH 做单表遍历计算的性能非常好,超过了 Ora 和 SPL,比如 TPC-H 的 Q1,对比情况如图 1: |
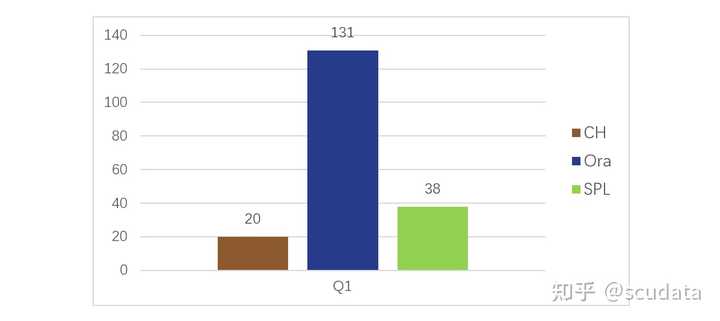
|
|
图 1:单表遍历简单查询性能比较(单位:秒) Q1 是单表遍历的简单分组汇总,CH 跑的最快,SPL 次之,Ora 最慢。 这个结果说明,CH 的列式存储做的不错,单表遍历速度快。SPL 也使用了列存,但速度赶不上 CH,这一方面是因为 SPL 存储压缩可能不如 CH,另一方面 Java 实现的 SPL 计算性能也弱于 C++ 写的 CH,而 SPL 的高性能算法在这个简单运算中也派不上用场。而 Ora 主要吃亏在使用了行式存储,明显要慢得多了。 二、对于稍微复杂一些的查询,CH 的表现就比较差了。比如, Q2、Q3、Q7,涉及到多表连接、子查询等相对复杂一些的查询,对比情况如图 2: |
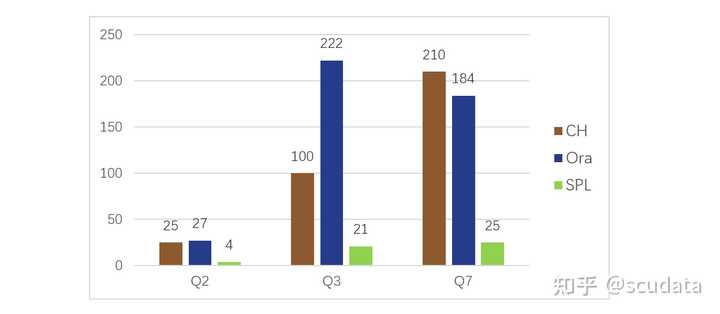
|
|
图 2:多表关联复杂查询性能比较(单位:秒) 这几个运算都是 SPL 最快。Q2 涉及数据量较少,列存作用不大,CH 性能和 Oracle 几乎一样。Q3 数据量较大,CH 还是占了列存的便宜后才超过了 Ora。Q7 数据也较大,但是计算复杂,CH 性能还不如 Ora。 在计算逻辑复杂之后,CH 的性能就开始急剧下降了。采用列式存储占了巨大的存储优势时,竟然能被 Ora 用行式存储赶上。这说明 CH 的算法优化能力很差,远远赶不上 Ora。而对于这些较复杂的运算,SPL 的算法优化就能得到体现,再加上列存优势,结果是 Java 写出来的程序跑赢了 C++ 写的 CH 和 Ora。 Q8 是更复杂一些的计算,子查询中有多表连接,CH 跑了 2000 多秒还没有出结果,应该是卡死了,Ora 跑了 192 秒,SPL 是 37 秒,最快。Q9 在 Q8 的子查询中增加了 like,CH 直接报内存不足的错误了,Ora 跑了 234 秒,SPL 是 68 秒,还是更快。其它还有些复杂运算是 CH 跑不出来的,就没法做个总体比较了。 综合上述测试来看,CH 并没有传说中那么神,简单的单表查询性能不错,复杂查询性能非常差。基本上可以断定,CH 的列式存储做得很好,但运算优化却可以说相当差。 对于希望用 CH 来提速的朋友,特别是希望能用 CH 来解决复杂查询甚至存储过程性能问题的朋友,那可能是想多了。 SPL 单表硬遍历比 CH 慢,但是复杂计算的性能却远远超过 CH。关键是,SPL 提供了丰富的数据类型,封装了大量的高性能算法,能用简洁的代码实现复杂计算。 对于复杂运算(包括存储过程),真有性能上的麻烦,SPL 才是最佳选择。 附:测试环境 CPU:2 颗 Intel3014,主频 1.7G,每个 CPU 内核数 6 个。 硬盘 (SSD):1T 561MB/s(读) 523MB/s(写) 接口:SATA 6.0Gb/s 内存:64G。 操作系统:Linux CentOS 7。 TPC-H 数据总规模 100G。所有测试都用 12 线程并行。 对开源SPL感兴趣的朋友,可以在这里联系小助手进SPL技术群交流讨论 |
|
ClickHouse 不神,但写 CH 的人很牛逼,这个牛逼一小部分是技术上,大部分在于毅力,十年如一日,超快速迭代,各种模板来怼算子。国内除了极少数真的就是靠技术吃饭的公司,不会有研发人员一直做这些事情的,做着做着就转管理了。 举一个 CH 不神的例子,CH 重构了 PipelineExecutor 的逻辑,用读写锁替换了原来的超搓看起来像 SpinLock 的 lock 来保护 ExpandPipeline。不知出于何种原因,这个读写锁是手写的,我肉眼就能看出有信号丢失的问题。随后我 Pull 了下 Master,换成 std::shared_mutex 了。 再比如,CH 的多线程是有点性能问题的,DAG 图上不同线程是可以抢算子的,这个对于有多线程经验的工程师一开始就会避免。 ClickHouse 路子是有点野的,代码只要看起来可以,就能进 Master,不会有太多顾虑,比如这个实现怎么才能降低出 Bug 的风险,是不是和现有系统自洽。这个可能也是 ClickHouse 的一个开源策略,快速演进使得所有 Fork 都压根跟不上,包含不限于 TiDB 的 TiFlash,字节的 ByteConity(ByteHouse)。 |
|
基于 ClickHouse version 22.10.1 学习并写下 ClickHouse 源码解析系列。由于 CK 版本迭代很快,可能导致代码可能有些出入,但是整体流程大差不差吧。由于源码阅读过于枯燥,并且不太利于后续复习,所以在逻辑梳理时,我会使用思维导图或者流程图的方式来描述类与类之间的调用逻辑,后半部分会挑出核心的源码去分析。 概述 第一篇我们就先从一个 SQL 的生命周期开始,从宏观上去看 CK 是如何处理 SQL 的。SQL 有 DML、DDL、DQL 多种语法,每种 SQL 的处理逻辑都不相同,但大体流程是类似的,我们主要以 InsertQuery、SelectQuery 两种 SQL 为例,窥探 SQL 在 CK 中的流转过程。本篇只是梳理整个 SQL 的调用流程,并不会细化分析一些细节实现(SQL 解析、查询计划生成、优化查询、表引擎的存储等),后续会具体分析。 逻辑梳理 SQL 执行(思维导图)?cii0nk6skx.feishu.cn/docx/HAp8dE6tKopJX9xXf1XcHfPgnvc#X6wid8UmMoQq6gxqgFOcMQi3njh 从上面的流程图中可以看出,整个 SQL 处理大致干了两件事情: 解析 SQL、构建 Pipeline;执行 Pipeline;解析 SQL、构建 Pipeline 这部分的核心处理逻辑在DB::executeQueryImpl()方法中,首先会解析 SQL 拿到 AST,这是一个通用的处理逻辑。接下来就会根据不同的 AST,使用相应的 Interpreter 去构建 Pipeline。 执行 Pipeline 在执行 Pipeline 时,会根据 pipeline 是 Push/Pull 模式分别处理不同的 SQL 语句。 以 OrdinaryQuery(查询语句...) 为例,PullingAsyncPipelineExecutor::pull(Block & block)方法会通过线程池,异步执行 Pipeline。 在PipelineExecutor::executeImpl(num_threads)方法中首先会调用PipelineExecutor::initializeExecution()初始化 ExecuteGraph 节点状态,并将可执行节点放入队列中等待线程处理。 在PipelineExecutor::executeStepImpl()方法中,会通过ExecutionThreadContext::executeTask()执行 IProcessor::work()方法完成数据处理,并且通过graph->updateNode()方法更新 ExecuteGraph 节点状态,尝试执行相邻的 Processor。 源码解析对 Pipeline 机制不了解的可以参考这篇博客:ClickHouse和他的朋友们(4)Pipeline处理器和调度器 SelectQuery 构建 QueryPipeline QueryPlan::buildQueryPipeline()方法会根据 QueryPlan 构建 QueryPipeline,我们以这样的一个 SelectQuery 为例:Select * From customer Limit 1。 下图是 SQL 生成的 QueryPlan 中的算子,这些算子在初始化完成后会被添加到 Pipeline 中,在阅读源码的时候可以带着这样一个想法:QueryPipeline 是由多个算子对应的 Transformer 连接起来的。 Pipe 是 Pipeline 的一部分,Pipe 包含多个 Processor,Transformer 是 Processor 的子类实现。 |

|
|
QueryPlan::buildQueryPipeline()源码: 该方法通过栈实现了 DFS 算法,算子不断入栈,终止条件是:当某个算子的所有 children 算子都完成 updatePipeline。算子的 updatePipeline 逻辑在IQueryPlanStep::updatePipeline()方法,这是一个虚函数。 对于举例的 SQL 来说,updatePipeline的顺序是:ReadFromMergeTree(ISourceStep) -> Limit(ITransformingStep) -> Expression(ITransformingStep)。 第一个算子ReadFromMergeTree会进入ISourceStep::updatePipeline()方法。 ISourceStep::updatePipeline()源码: 在 QueryPipelineBuilder 中有一个 processors 变量,在每个 IXxxStep 中也保存了一份 processors,这个 processors 收集了每个算子 updatepipeline 时得到的 Processor。 后续的算子Limit、Expression会进入ITransformingStep::updatePipeline()方法。 ITransformingStep::updatePipeline()源码: 通过上面流程就可以根据 QueryPlan 构建出一个完整的 QueryPipeline(也就是最后返回的 last_pipeline)。 第一个算子的updatePipeline()方法中会调用initializePipeline(),后续的算子的updatePipeline()方法会调用transformPipeline()方法。想想也合理,第一个算子初始化 Pipeline,后续算子只需要把 Transformer 往 Pipeline 里面拼接就行了。 以ReadFromMergeTree这个 Storage 为例,它会在它的initializePipeline()实现方法中,调用Pipe ReadFromMergeTree::read()方法,在进一步调用ReadFromMergeTree::readInOrder()方法。 ReadFromMergeTree::readInOrder()源码(省略部分代码): 在该方法中,会将MergeTreeInOrderSelectProcessor这个实现了 IProcessor 接口的 ISource 放入 Pipe 中,然后返回。紧接着会调用到第二个算子LimitStep,我们直接来到它的transformPipeline()方法的具体实现。 LimitStep::transformPipeline()源码: 介个方法灰常简单,就是创建了算子对应的 Transformer[LimitTransform],然后把它加入到 Pipeline 就完事了。 至此,一个 SelectQuery 的 QueryPipeline 就构建出来了,可能看到这里对于 CK Pipeline 的 Pull/Push 模式有点懵,下一篇进一步学习 QueryPipeline 是如何在 ClickHouse 内部被调度运转的,它的数据是如何流动的。 |
|
1 前言 |
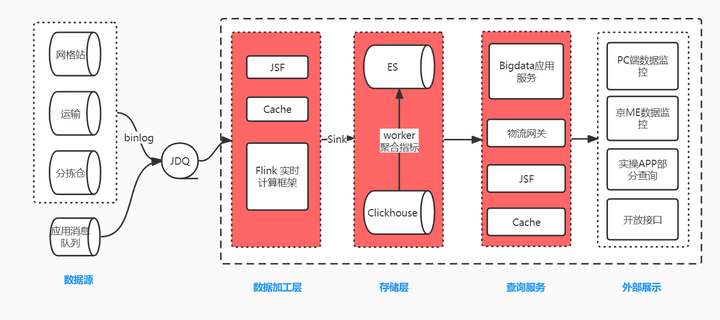
|
|
京喜达技术部在社区团购场景下采用 JDQ+Flink+Elasticsearch 架构来打造实时数据报表。随着业务的发展 Elasticsearch 开始暴露出一些弊端,不适合大批量的数据查询,高频次深度分页导出导致 ES 宕机、不能精确去重统计,多个字段聚合计算时性能下降明显。所以引入 ClickHouse 来处理这些弊端。 数据写入链路是业务数据 (binlog) 经过处理转换成固定格式的 MQ 消息,Flink 订阅不同 Topic 来接收不同生产系统的表数据,进行关联、计算、过滤、补充基础数据等加工关联汇总成宽表,最后将加工后的 DataStream 数据流双写入 ES 和 ClickHouse。查询服务通过 JSF 和物流网关对外暴露提供给外部进行展示,由于 ClickHouse 将所有计算能力都用在一次查询上,所以不擅长高并发查询。我们通过对部分实时聚合指标接口增加缓存,或者定时任务查询 ClickHosue 计算指标存储到 ES,部分指标不再实时查 ClickHouse 而是查 ES 中计算好的指标来抗住并发,并且这种方式能够极大提高开发效率,易维护,能够统一指标口径。 在引入 ClickHouse 过程中经历各种困难,耗费大量精力去探索并一一解决,在这里记录一下希望能够给没有接触过 ClickHouse 的同学提供一些方向上的指引避免多走弯路,如果文中有错误也希望多包含给出指点,欢迎大家一起讨论 ClickHouse 相关的话题。本文偏长但全是干货,请预留 40~60 分钟进行阅读。 2 遇到的问题 前文说到遇到了很多困难,下面这些遇到的问题是本文讲述的重点内容。 我们该使用什么表引擎Flink 如何写入到 ClickHouse查询 ClickHouse 为什么要比查询 ES 慢 1~2 分钟写入分布式表还是本地表为什么只有某个分片 CPU 使用率高如何定位是哪些 SQL 在消耗 CPU,这么多慢 SQL,我怎么知道是哪个 SQL 引起的找到了慢 SQL,如何进行优化如何抗住高并发、保证 ClickHouse 可用性3 表引擎选择与查询方案 在选择表引擎以及查询方案之前,先把需求捋清楚。前言中说到我们是在 Flink 中构造宽表,在业务上会涉及到数据的更新的操作,会出现同一个业务单号多次写入数据库。ES 的 upsert 支持这种需要覆盖之前数据的操作,ClickHouse 中没有 upsert,所以需要探索出能够支持 upsert 的方案。带着这个需求来看一下 ClickHouse 的表引擎以及查询方案。 ClickHouse 有很多表引擎,表引擎决定了数据以什么方式存储,以什么方式加载,以及数据表拥有什么样的特性。目前 ClickHouse 表引擎一共分为四个系列,分别是 Log、MergeTree、Integration、Special。 Log 系列:适用于少量数据 (小于一百万行) 的场景,不支持索引,所以对于范围查询效率不高。Integration 系列:主要用于导入外部数据到 ClickHouse,或者在 ClickHouse 中直接操作外部数据,支持 Kafka、HDFS、JDBC、Mysql 等。Special 系列:比如 Memory 将数据存储在内存,重启后会丢失数据,查询性能极好,File 直接将本地文件作为数据存储等大多是为了特定场景而定制的。MergeTree 系列:MergeTree 家族自身拥有多种引擎的变种,其中 MergeTree 作为家族中最基础的引擎提供主键索引、数据分区、数据副本和数据采样等能力并且支持极大量的数据写入,家族中其他引擎在 MergeTree 引擎的基础上各有所长。 Log、Special、Integration 主要用于特殊用途,场景相对有限。其中最能体现 ClickHouse 性能特点的是 MergeTree 及其家族表引擎,也是官方主推的存储引擎,几乎支持所有 ClickHouse 核心功能,在生产环境的大部分场景中都会使用此系列的表引擎。我们的业务也不例外需要使用主键索引,日数据增量在 2500 多万的增量,所以 MergeTree 系列是我们需要探索的目标。 MergeTree 系列的表引擎是为插入大量数据而生,数据是以数据片段的形式一个接一个的快速写入,ClickHouse 为了避免数据片段过多会在后台按照一定的规则进行合并形成新的段,相比在插入时不断的修改已经存储在磁盘的数据,这种插入后合并再合并的策略效率要高很多。这种数据片段反复合并的特点,也正是 MergeTree 系列 (合并树家族) 名称的由来。为了避免形成过多的数据片段,需要进行批量写入。MergeTree 系列包含 MergeTree、ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree、SummingMergeTree、AggregatingMergeTree 引擎,下面就介绍下这几种引擎。 3.1 MergeTree:合并树 MergeTree 支持所有 ClickHouse SQL 语法。大部分功能点和我们熟悉的 MySQL 是类似的,但是有些功能差异比较大,比如主键,MergeTree 系列的主键并不用于去重,MySQL 中一个表中不能存在两条相同主键的数据,但是 ClickHouse 中是可以的。 下面建表语句中,定义了订单号,商品数量,创建时间,更新时间。按照创建时间进行数据分区,orderNo 作为主键 (primary key),orderNo 也作为排序键 (order by),默认情况下主键和排序键相同,大部分情况不需要再专门指定 primary key,这个例子中指定只是为了说明下主键和排序键的关系。当然排序键可以与的主键字段不同,但是主键必须为排序键的子集,例如主键 (a,b), 排序键必须为 (a,b, , ),并且组成主键的字段必须在排序键字段中的最左侧。 注意这里写入的两条数据主键 orderNo 都是 1 的两条数据,这个场景是我们先创建订单,再更新了订单的商品数量为 30 和更新时间,此时业务实际订单量为 1,商品件量是 30。 插入主键相同的数据不会产生冲突,并且查询数据两条相同主键的数据都存在。下图是查询结果,由于每次插入都会形成一个 part,第一次 insert 生成了 1609430400_1_1_0 数据分区文件,第二次 insert 生成了 1609430400_2_2_0 数据分区文件,后台还没触发合并,所以在 clickhouse-client 上的展示结果是分开两个表格的 (图形化查询工具 DBeaver、DataGrip 不能看出是两个表格,可以通过 docker 搭建 ClickHouse 环境通过 client 方式执行语句,文末有搭建 CK 环境文档)。 |

|
|
预期结果应该是 number 从 20 更新成 30,updateTime 也会更新成相应的值,同一个业务主键只存在一行数据,可是最终是保留了两条。Clickhouse 中的这种处理逻辑会导致我们查询出来的数据是不正确的。比如去重统计订单数量,count (orderNo),统计下单件数 sum (number)。 |
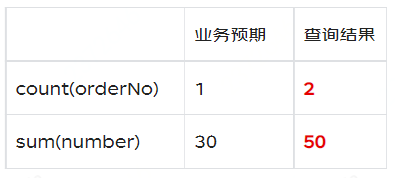
|
|
下面尝试将两行数据进行合并。 |

|
|
进行强制的分段合并后,还是有两条数据,并不是我们预期的保留最后一条商品数量为 30 的数据。但是两行数据合并到了一个表格中,其中的原因是 1609430400_1_1_0,1609430400_2_2_0 的 partitionID 相同合并成了 1609430400_1_2_1 这一个文件。合并完成后其中 1609430400_1_1_0,1609430400_2_2_0 会在一定时间 (默认 8min) 后被后台删除。下图是分区文件的命名规则,partitionID:1609430400 = 2021-01-01 00:00:00,MinBolckNum、MaxBolckNum:是最小数据块最大数据块,是一个整形自增的编号。Level:0 可以理解为分区合并过的次数,默认值是 0,每次合并过后生成的新的分区后会加 1。 |
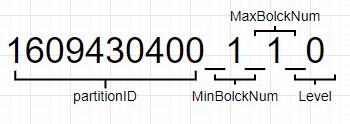
|
|
综合上述,可以看出 MergeTree 虽然有主键,但并不是类似 MySQL 用来保持记录唯一的去重作用,只是用来查询加速,即使在手动合并之后,主键相同的数据行也仍旧存在,不能按业务单据去重导致 count (orderNo),sum (number) 拿到的结果是不正确的,不适用我们的需求。 3.2 ReplacingMergeTree:替换合并树 MergeTree 虽然有主键,但是不能对相同主键的数据进行去重,我们的业务场景不能有重复数据。ClickHouse 提供了 ReplacingMergeTree 引擎用来去重,能够在合并分区时删除重复的数据。我理解的去重分两个方面,一个是物理去重,就是重复的数据直接被删除掉,另一个是查询去重,不处理物理数据,但是查询结果是已经将重复数据过滤掉的。 示例如下,ReplacingMergeTree 建表方法和 MergeTree 没有特别大的差异,只是 ENGINE 由 MergeTree 更改为 ReplacingMergeTree ([ver]),其中 ver 是版本列,是一个选填项,官网给出支持的类型是 UInt ,Date 或者 DateTime,但是我试验 Int 类型也是可以支持的 (ClickHouse 20.8.11)。ReplacingMergeTree 在数据合并时物理数据去重,去重策略如下。 如果 ver 版本列未指定,相同主键行中保留最后插入的一行。如果 ver 版本列已经指定,下面实例就指定了 version 列为版本列,去重是将会保留 version 值最大的一行,与数据插入顺序无关。 <!----> 下图是在执行完前两条 insert 语句后进行三次查询的结果,三种方式查询均未对物理存储的数据产生影响,final、argMax 方式只是查询结果是去重的。 普通查询:查询结果未去重,物理数据未去重 (未合并分区文件)final 去重查询:查询结果已去重,物理数据未去重 (未合并分区文件)argMax 去重查询:查询结果已去重,物理数据未去重 (未合并分区文件) |

|
|
其中 final 和 argMax 查询方式都过滤掉了重复数据。我们的示例都是基于本地表做的操作,final 和 argMax 在结果上没有差异,但是如果基于分布式表进行试验,两条数据落在了不同数据分片 (注意这里不是数据分区),那么 final 和 argMax 的结果将会产生差异。final 的结果将是未去重的,原因是 final 只能对本地表做去重查询,不能对跨分片的数据进行去重查询,但是 argMax 的结果是去重的。argMax 是通过比较第二参数 version 的大小,来取出我们要查询的最新数据来达到过滤掉重复数据的目的,其原理是将每个 Shard 的数据搂到同一个 Shard 的内存中进行比较计算,所以支持跨分片的去重。 由于后台的合并是在不确定时间执行的,执行合并命令,然后再使用普通查询,发现结果已经是去重后的数据,version=2,number=30 是我们想保留的数据。 |
|
|
执行第三条 insert 语句,第三条的主键和前两条一致,但是分区字段 createTime 字段不同,前两条是 2021-01-01 00:00:00,第三条是 2021-01-02 00:00:00,如果按照上述的理解,在强制合并会后将会保留 version = 3 的这条数据。我们执行普通查询之后发现,version = 1 和 2 的数据做了合并去重,保留了 2,但是 version=3 的还是存在的,这其中的原因 ReplacingMergeTree 是已分区为单位删除重复数据。前两个 insert 的分区字段 createTime 字段相同,partitionID 相同,所以都合并到了 1609430400_1_2_1 分区文件,而第三条 insert 与前两条不一致,不能合并到一个分区文件,不能做到物理去重。最后通过 final 去重查询发现可以支持查询去重,argMax 也是一样的效果未作展示。 |

|
|
ReplacingMergeTree 具有如下特点 使用主键作为判断重复数据的唯一键,支持插入相同主键数据。在合并分区的时候会触发删除重复数据的逻辑。但是合并的时机不确定,所以在查询的时候可能会有重复数据,但是最终会去重。可以手动调用 optimize,但是会引发对数据大量的读写,不建议生产使用。以数据分区为单位删除重复数据,当分区合并时,同一分区内的重复数据会被删除,不同分区的重复数据不会被删除。可以通过 final,argMax 方式做查询去重,这种方式无论有没有做过数据合并,都可以得到正确的查询结果。 ReplacingMergeTree 最佳使用方案 普通 select 查询:对时效不高的离线查询可以采用 ClickHouse 自动合并配合,但是需要保证同一业务单据落在同一个数据分区,分布式表也需要保证在同一个分片 (Shard),这是一种最高效,最节省计算资源的查询方式。final 方式查询:对于实时查询可以使用 final,final 是本地去重,需要保证同一主键数据落在同一个分片 (Shard),但是不需要落在同一个数据分区,这种方式效率次之,但是与普通 select 相比会消耗一些性能,如果 where 条件对主键索引,二级索引,分区字段命中的比较好的话效率也可以完全可以使用。argMax 方式查询:对于实时查询可以使用 argMax,argMax 的使用要求最低,咋查都能去重,但是由于它的实现方式,效率会低很多,也很消耗性能,不建议使用。后面 9.4.3 会配合压测数据与 final 进行对比。 上述的三种使用方案中其中 ReplacingMergeTree 配合 final 方式查询,是符合我们需求的。 3.3 CollapsingMergeTree/VersionedCollapsingMergeTree:折叠合并树 折叠合并树不再通过示例来进行说明。可参考官网示例。 |
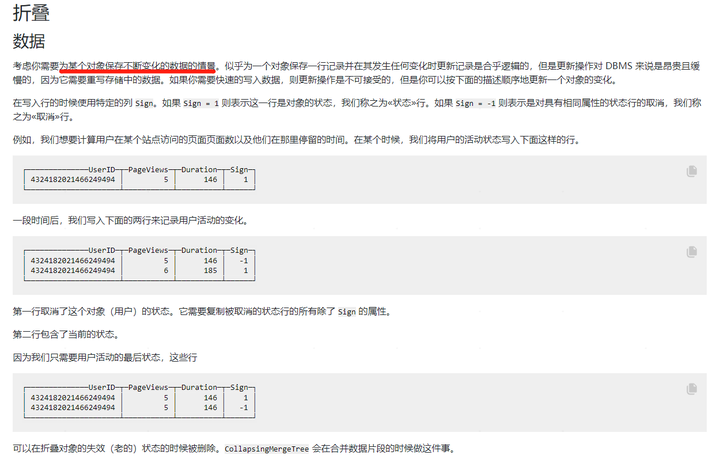
|
|
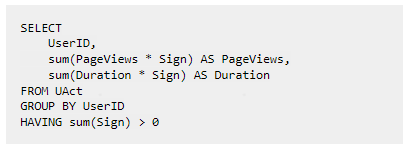
CollapsingMergeTree 通过定义一个 sign 标记位字段,记录数据行的状态。如果 sign 标记位 1 (《状态》行), 则表示这是一行有效的数据, 如果 sign 标记位为 -1 (《取消》行),则表示这行数据需要被删除。需要注意的是数据主键相同才可能会被折叠。 如果 sign=1 比 sign=-1 的数据多至少一行,则保留最后一行 sign=1 的数据。如果 sign=-1 比 sign=1 多至少一行,则保留第一行 sign=-1 的行。如果 sign=1 与 sign=-1 的行数一样多,最后一行是 sign=1,则保留第一行 sign=-1 和最后一行 sign=1 的数据。如果 sign=1 与 sign=-1 的行数一样多,最后一行是 sign=-1,则什么都不保留。其他情况 ClickHouse 不会报错但会打印告警日志,这种情况下,查询的结果是不确定不可预知的。 在使用 CollapsingMergeTree 时候需要注意 1)与 ReplacingMergeTree 一样,折叠数据不是实时触发的,是在分区合并的时候才会体现,在合并之前还是会查询到重复数据。解决方式有两种 使用 optimize 强制合并,同样也不建议在生产环境中使用效率极低并且消耗资源的强制合并。改写查询方式,通过 group by 配合有符号的 sign 列来完成。这种方式增加了使用的编码成本 |
|
|
2)在写入方面通过《取消》行删除或修改数据的方式需要写入数据的程序记录《状态》行的数据,极大的增加存储成本和编程的复杂性。Flink 在上线或者某些情况下会重跑数据,会丢失程序中的记录的数据行,可能会造成 sign=1 与 sign=-1 不对等不能进行合并,这一点是我们无法接受的问题。 CollapsingMergeTree 还有一个弊端,对写入的顺序有严格的要求,如果按照正常顺序写入,先写入 sign=1 的行再写入 sign=-1 的行,能够正常合并,如果顺序反过来则不能正常合并。ClickHouse 提供了 VersionedCollapsingMergeTree,通过增加版本号来解决顺序问题。但是其他的特性与 CollapsingMergeTree 完全一致,也不能满足我们的需求 3.4 表引擎总结 我们详细介绍了 MergeTree 系列中的 MergeTree、ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree 四种表引擎,还有 SummingMergeTree、AggregatingMergeTree 没有介绍,SummingMergeTree 是为不关心明细数据,只关心汇总数据设计的表引擎。MergeTree 也能够满足这种只关注汇总数据的需求,通过 group by 配合 sum,count 聚合函数就可以满足,但是每次查询都进行实时聚合会增加很大的开销。我们既有明细数据需求,又需要汇总指标需求,所以 SummingMergeTree 不能满足我们的需求。AggregatingMergeTree 是 SummingMergeTree 升级版,本质上还是相同的,区别在于:SummingMergeTree 对非主键列进行 sum 聚合,而 AggregatingMergeTree 则可以指定各种聚合函数。同样也满足不了需求。 |

|
|
最终我们选用了 ReplacingMergeTree 引擎,分布式表通过业务主键 sipHash64 (docId) 进行 shard 保证同一业务主键数据落在同一分片,同时使用业务单据创建时间按月 / 按天进行分区。配合 final 进行查询去重。这种方案在双十一期间数据日增 3000W,业务高峰数据库 QPS93,32C 128G 6 分片 2 副本的集群 CPU 使用率最高在 60%,系统整体稳定。下文的所有实践优化也都是基于 ReplacingMergeTree 引擎。 4 Flink 如何写入 ClickHouse4.1 Flink 版本问题 Flink 支持通过 JDBC Connector 将数据写入 JDBC 数据库,但是 Flink 不同版本的 JDBC connector 写入方式有很大区别。因为 Flink 在 1.11 版本对 JDBC Connector 进行了一次较大的重构: 1.11 版本之前包名为 flink-jdbc1.11 版本 (包含) 之后包名为 flink-connector-jdbc 两者对 Flink 中以不同方式写入 ClickHouse Sink 的支持情况如下: |
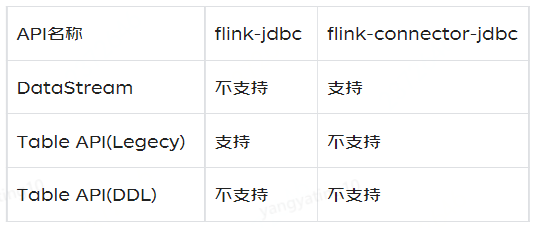
|
|
起初我们使用 1.10.3 版本的 Flink,flink-jdbc 不支持使用 DataStream 流写入,需要升级 Flink 版本至 1.11.x 及以上版本来使用 flink-connector-jdbc 来写入数据到 ClickHouse。 4.2 构造 ClickHouse Sink 使用 flink-connector-jdbc 的 JdbcSink.sink () api 来构造 Flink sink。JdbcSink.sink () 入参含义如下 sql:占位符形式的 sql 语句,例如:insert into demo (id, name) values (?, ?)new CkSinkBuilder<>():org.apache.flink.connector.jdbc.JdbcStatementBuilder 接口的实现类,主要是将流中数据映射到 java.sql.PreparedStatement 来构造 PreparedStatement ,具体不再赘述。第三个入参:flink sink 的执行策略。第四个入参:jdbc 的驱动,连接,账号与密码。 |

|
|
使用时直接在 DataStream 流中 addSink 即可。5 Flink 写入 ClickHouse 策略 Flink 同时写入 ES 和 Clikhouse,但是在进行数据查询的时候发现 ClickHouse 永远要比 ES 慢一些,开始怀疑是 ClickHouse 合并等处理会耗费一些时间,但是 ClickHouse 这些合并操作不会影响查询。后来查阅 Flink 写入策略代码发现是我们使用的策略有问题。 上段 (4.2) 代码中 new JdbcExecutionOptions.Builder ().withBatchSize (200000).build () 为写入策略,ClickHouse 为了提高写入性能建议进行不少于 1000 行的批量写入,或每秒不超过一个写入请求。策略是 20W 行记录进行写入一次,Flink 进行 Checkpoint 的时候也会进行写入提交。所以当数据量积攒到 20W 或者 Flink 记性 Checkpoint 的时候 ClickHouse 里面才会有数据。我们的 ES sink 策略是 1000 行或 5s 进行写入提交,所以出现了写入 ClickHouse 要比写入 ES 慢的现象。 到达 20W 或者进行 Checkpoint 的时候进行提交有一个弊端,当数据量小达不到 20W 这个量级,Checkpoint 时间间隔 t1,一次 checkpoint 时间为 t2,那么从接收到 JDQ 消息到写入到 ClickHouse 最长时间间隔为 t1+t2,完全依赖 Checkpoint 时间,有时候有数据积压最慢有 1~2min。进而对 ClickHouse 的写入策略进行优化,new JdbcExecutionOptions.Builder ().withBatchIntervalMs (30 * 1000).build () 优化为没 30s 进行提交一次。这样如果 Checkpoint 慢的话可以触发 30s 提交策略,否则 Checkpoint 的时候提交,这也是一种比较折中的策略,可以根据自己的业务特性进行调整,在调试提交时间的时候发现如果间隔过小,zookeeper 的 cpu 使用率会提升,10s 提交一次 zk 使用率会从 5% 以下提升到 10% 左右。 Flink 中的 org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat#open 处理逻辑如下图。 |

|
|
6 写入分布式表还是本地表 先说结果,我们是写入分布式表。 网上的资料和 ClickHouse 云服务的同事都建议写入本地表。分布式表实际上是一张逻辑表并不存储真实的物理数据。如查询分布式表,分布式表会把查询请求发到每一个分片的本地表上进行查询,然后再集合每个分片本地表的结果,汇总之后再返回。写入分布式表,分布式表会根据一定规则,将写入的数据按照规则存储到不同的分片上。如果写入分布式表也只是单纯的网络转发,影响也不大,但是写入分布式表并非单纯的转发,实际情况见下图。 |
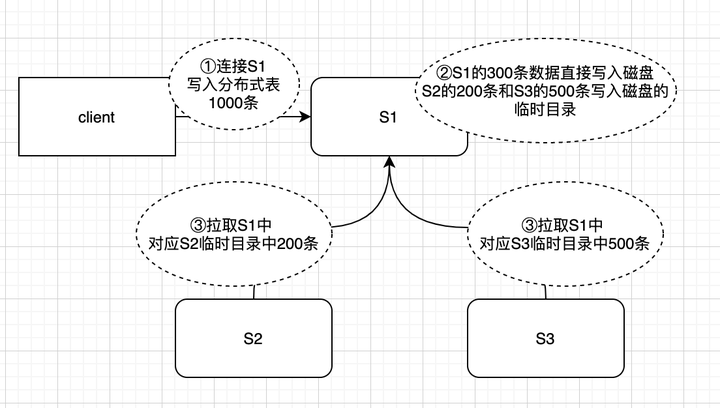
|
|
有三个分片 S1、S2、S3,客户端连接到 S1 节点,进行写入分布式表操作。 第一步:写入分布式表 1000 条数据,分布式表会根据路由规则,假设按照规则 300 条分配到 S1,200 条到 S2,500 条到 S3第二步:client 给过来 1000 条数据,属于 S1 的 300 条数据直接写入磁盘,数据 S2,S3 的数据也会写入到 S1 的临时目录第三步:S2,S3 接收到 zk 的变更通知,生成拉取 S1 中当前分片对应的临时目录数据的任务,并且将任务放到一个队列,等到某个时机会将数据拉到自身节点。 从分布式表的写入方式可以看到,会将所有数据落到 client 连接分片的磁盘上。如果数据量大,磁盘的 IO 会造成瓶颈。并且 MergeTree 系列引擎存在合并行为,本身就有写放大 (一条数据合并多次),占用一定磁盘性能。在网上看到写入本地表的案例都是日增量百亿,千亿。我们选择写入分布式表主要有两点,一是简单,因为写入本地表需要改造代码,自己指定写入哪个节点,另一个是开发过程中写入本地表并未出现什么严重的性能瓶颈。双十一期间数据日增 3000W (合并后) 行并未造成写入压力。如果后续产生瓶颈,可能会放弃写入分布式表。 7 为什么只有某个分片 CPU 使用率高7.1 数据分布不均匀,导致部分节点 CPU 高 |
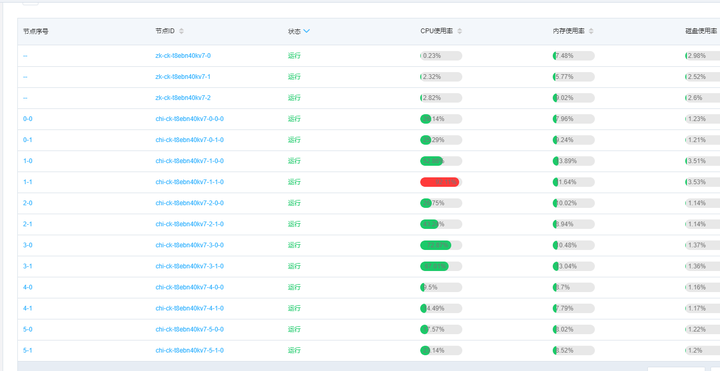
|
|
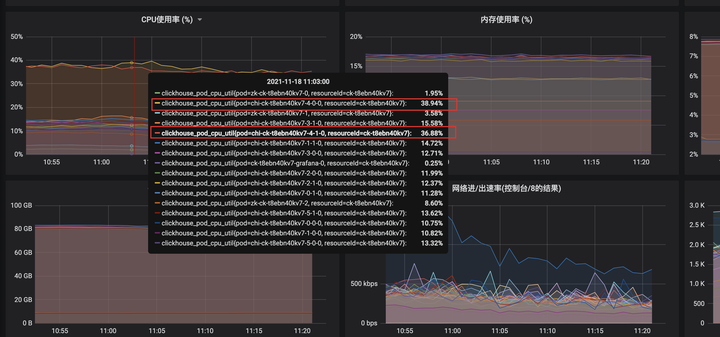
上图是在接入 ClickHouse 过程中遇到的一个问题,其中 7-1 节点 CPU 使用率非常高,不同节点的差异非常大。后来通过 SQL 定位发现不同节点上的数据量差异也非常大,其中 7-1 节点数据量是最多的,导致 7-1 节点相比其他节点需要处理的数据行数非常多,所以 CPU 相对会高很多。因为我们使用网格站编码,分拣仓编码 hash 后做分布式表的数据分片策略,但是分拣仓编码和网站编码的基数比较小,导致 hash 后不够分散造成这种数据倾斜的现象。后来改用业务主键做 hash,解决了这种部分节点 CPU 高的问题。 7.2 某节点触发合并,导致该节点 CPU 高 |
|
|
7-4 节点 (主节点和副本),CPU 毫无征兆的比其他节点高很多,在排除新业务上线、大促等突发情况后进行慢 SQL 定位,通过 query_log 进行分析每个节点的慢查询,具体语句见第 8 小节。 |
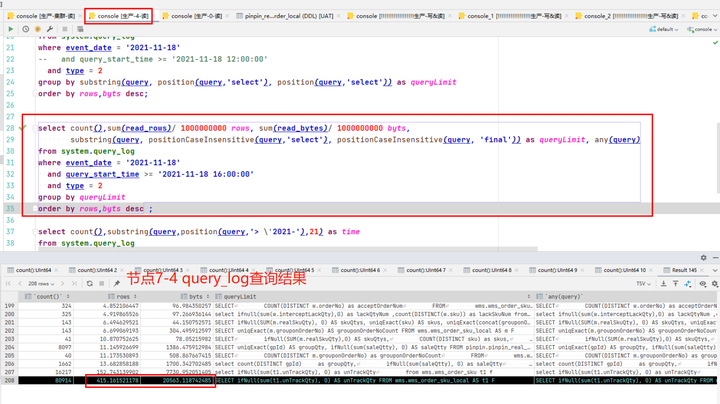
|
|
|
|
|
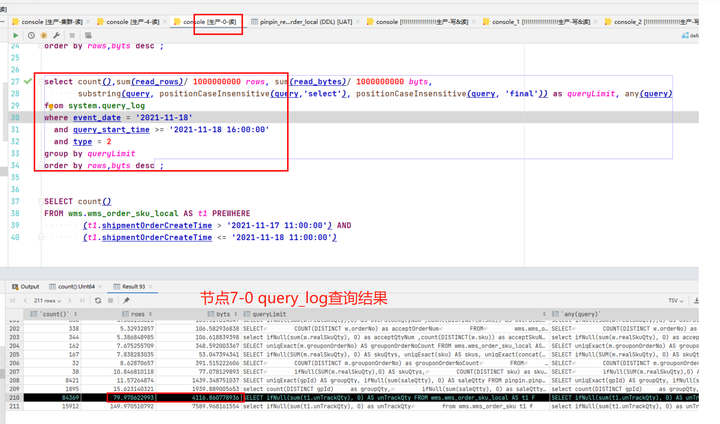
通过两个节点的慢 SQL 进行对比,发现是如下 SQL 的查询情况有较大差异。 但是我们有个疑惑,同样的语句,同样的执行次数,而且两个节点的数据量,part 数量都没有差异,为什么 7-4 节点扫描的行数是 7-0 上的 5 倍,把这个原因找到,应该就能定位到问题的根本原因了。 接下来我们使用 clickhouse-client 进行 SQL 查询,开启 trace 级别日志,查看 SQL 的执行过程。具体执行方式以及查询日志分析参考下文 9.1 小节,这里我们直接分析结果。 |
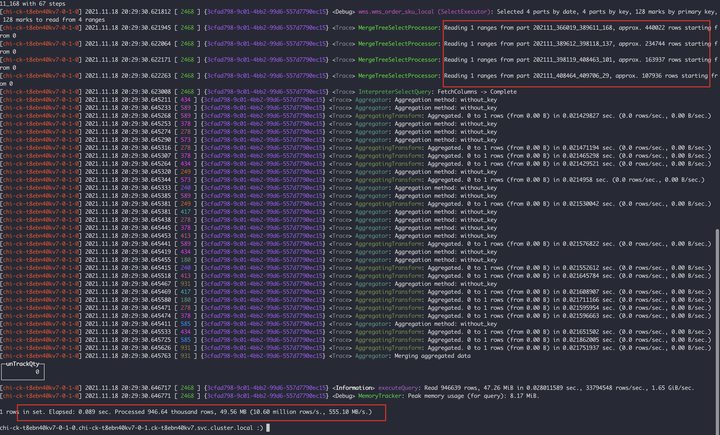
|
|
|
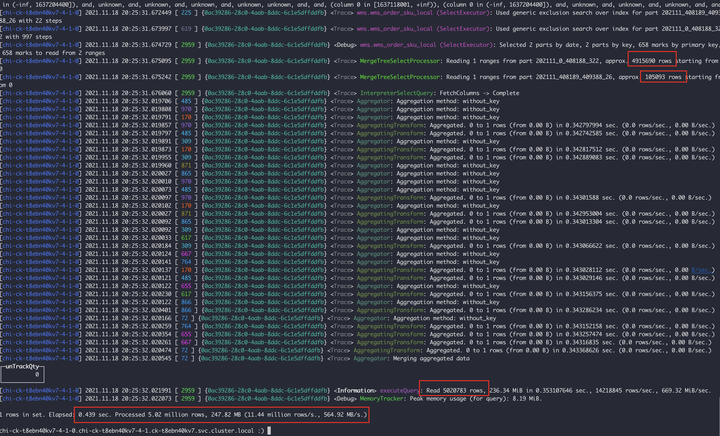
|
|
上面两张图可以分析出 7-0 节点:扫描了 4 个 part 分区文件,共计 94W 行,耗时 0.089s7-4 节点:扫描了 2 个 part 分区文件,其中有一个 part491W 行,共计 502W 行,耗时 0.439s 很明显 7-4 节点的 202111_0_408188_322 这个分区比较异常,因为我们是按月分区的,7-4 节点不知道什么原因发生了分区合并,导致我们检索的 11 月 17 号的数据落到了这个大分区上,所以但是查询会过滤 11 月初到 18 号的所有数据,和 7-0 节点产生了差异。上述的 SQL 通过 gridStationNo = ‘WG0000514’ 条件进行查询,所以在对 gridStationNo 字段进行创建二级索引后解决了这个问题。 |
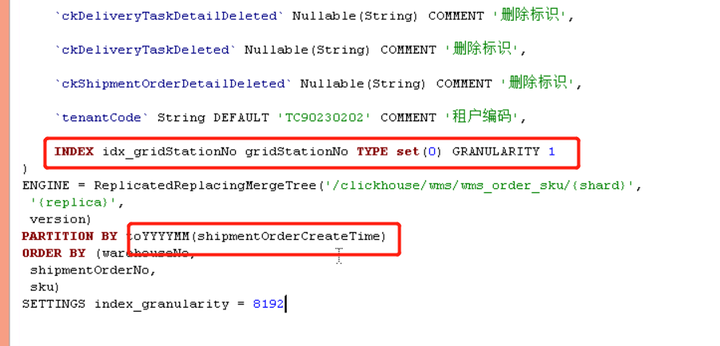
|
|
|
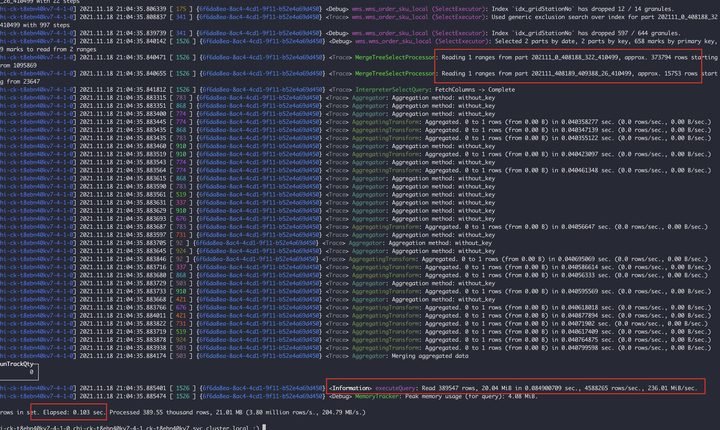
|
|
在增加加二级索引后 7-4 节点:扫描了 2 个 part 分区文件,共计 38W 行,耗时 0.103s。 7.3 物理机故障 这种情况少见,但是也遇到过一次 |
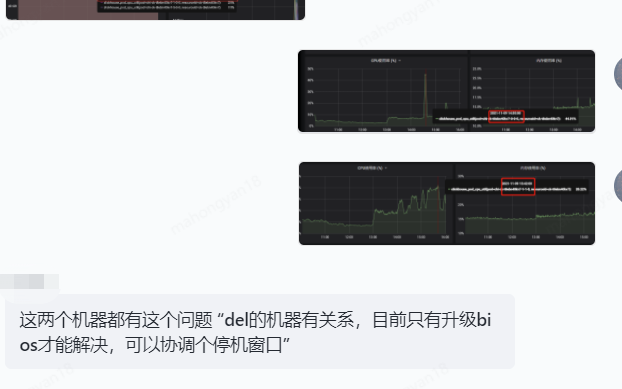
|
|
8 如何定位是哪些 SQL 在消耗 CPU 我认为可以通过两个方向来排查问题,一个是 SQL 执行频率是否过高,另一个方向是判断是否有慢 SQL 在执行,高频执行或者慢查询都会大量消耗 CPU 的计算资源。下面通过两个案例来说明一下排查 CPU 偏高的两种有效方法,下面两种虽然操作上是不同的,但是核心都是通过分析 query_log 来进行分析定位的。 8.1 grafana 定位高频执行 SQL 在 12 月份上线了一些需求,最近发现 CPU 使用率对比来看使用率偏高,需要排查具体是哪些 SQL 导致的。 |
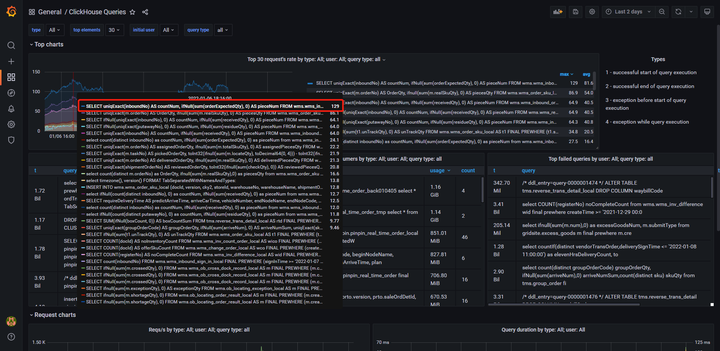
|
|
通过上图自行搭建的 grafana 监控可以看出 (搭建文档),有几个查询语句执行频率非常高,通过 SQL 定位到查询接口代码逻辑,发现一次前端接口请求后端接口会执行多条相似条件的 SQL 语句,只是业务状态不相同。这种需要统计不同类型、不同状态的语句,可以进行条件聚合进行优化,9.4.1 小节细讲。优化后语句执行频率极大的降低。 |

|
|
8.2 扫描行数高 / 使用内存高:query_log_all 分析 上节说 SQL 执行频率高,导致 CPU 使用率高。如果 SQL 频率执行频率很低很低,但是 CPU 还是很高该怎么处理。SQL 执行频率低,可能存在扫描的数据行数很大的情况,消耗的磁盘 IO,内存,CPU 这些资源很大,这种情况下就需要换个手段来排查出来这个很坏很坏的 SQL (T?T)。 ClickHouse 自身有 system.query_log 表,用于记录所有的语句的执行日志,下图是该表的一些关键字段信息 |
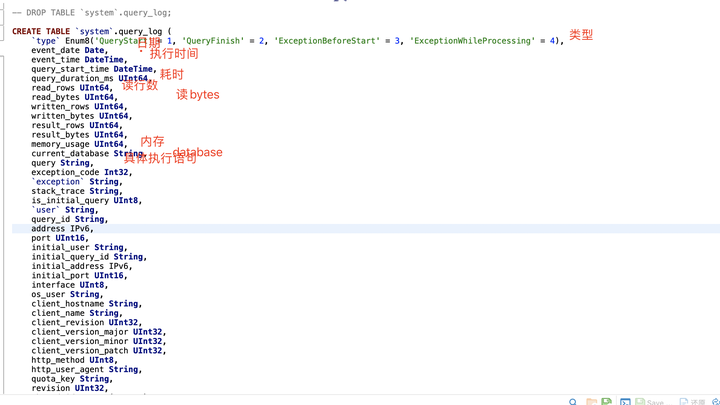
|
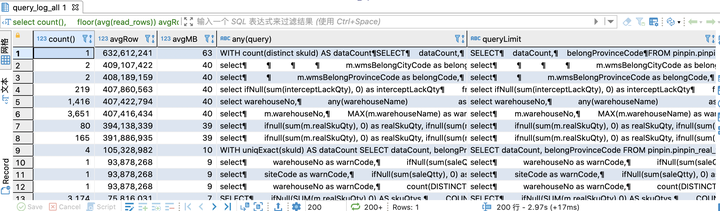
query_log 是本地表,需要创建分布式表,查询所有节点的查询日志,然后再执行查询分析语句,执行效果见下图,图中可以看出有几个语句平均扫秒行数已经到了亿级别,这种语句可能就存在问题。通过扫描行数可以分析出索引,查询条件等不合理的语句。7.2 中的某个节点 CPU 偏高就是通过这种方式定位到有问题的 SQL 语句,然后进一步排查从而解决的。 |
|
|
9 如何优化慢查询 ClickHouse 的 SQL 优化比较简单,查询的大部分耗时都在磁盘 IO 上,可以参考下这个小实验来理解。核心优化方向就是降低 ClickHouse 单次查询处理的数据量,也就是降低磁盘 IO。下面介绍下慢查询分析手段、建表语句优化方式,还有一些查询语句优化。 9.1 使用服务日志进行慢查询分析 虽然 ClickHouse 在 20.6 版本之后已经提供查看查询计划的原生 EXPLAIN,但是提供的信息对我们进行慢 SQL 优化提供的帮助不是很大,在 20.6 版本前借助后台的服务日志,可以拿到更多的信息供我们分析。与 EXPLAIN 相比我更倾向于使用查看服务日志这种方式进行分析,这种方式需要使用 clickhouse-client 进行执行 SQL 语句,文末有通过 docker 搭建 CK 环境文档。高版本的 EXPLAIN 提供了 ESTIMATE 可以查询到 SQL 语句扫描的 part 数量、数据行数等细粒度信息,EXPLAIN 使用方式可以参考官方文档说明。 用一个慢查询来进行分析,通过 8.2 中的 query_log_all 定位到下列慢 SQL。 使用 clickhouse-client,send_logs_level 参数指定日志级别为 trace。 在 client 中执行上述慢 SQL,服务端打印日志如下,日志量较大,省去部分部分行,不影响整体日志的完整性。 现在分析下,从上述日志中能够拿到什么信息,首先该查询语句没有使用主键索引,具体信息如下 2022.02.17 21:21:54.038239 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Key condition: unknown, unknown, and, unknown, unknown, and, and, unknown, unknown, and, and 同样也没有使用分区索引,具体信息如下 2022.02.17 21:21:54.038271 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): MinMax index condition: unknown, unknown, and, unknown, unknown, and, and, unknown, unknown, and, and 此次查询一共扫描 36 个 parts,9390 个 MarkRange,通过查询 system.parts 系统分区信息表发现当前表一共拥有 36 个活跃的分区,相当于全表扫描。 2022.02.17 21:44:58.012832 [ 1138 ] {f1561330-4988-4598-a95d-bd12b15bc750} wms.wms_order_sku_local (SelectExecutor): Selected 36 parts by date, 36 parts by key, 9390 marks by primary key, 9390 marks to read from 36 ranges |

|
|
此次查询总共读取了 73645604 行数据,这个行数也是这个表的总数据行数,读取耗时 0.229100749s,共读取 1.20GB 的数据。 2022.02.17 21:21:54.265490 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} executeQuery: Read 73645604 rows, 1.20 GiB in 0.229100749 sec., 321455099 rows/sec., 5.22 GiB/sec. 此次查询语句消耗的内存最大为 60.37MB 2022.02.17 21:21:54.265551 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MemoryTracker: Peak memory usage (for query): 60.37 MiB. 最后汇总了下信息,此次查询总共耗费了 0.267s,处理了 7365W 数据,共 1.28GB,并且给出了数据处理速度。 1 rows in set. Elapsed: 0.267 sec. Processed 73.65 million rows, 1.28 GB (276.03 million rows/s., 4.81 GB/s.) 通过上述可以发现两点严重问题 没有使用主键索引:导致全表扫描没有使用分区索引:导致全表扫描 所以需要再查询条件上添加主键字段或者分区索引来进行优化。 |
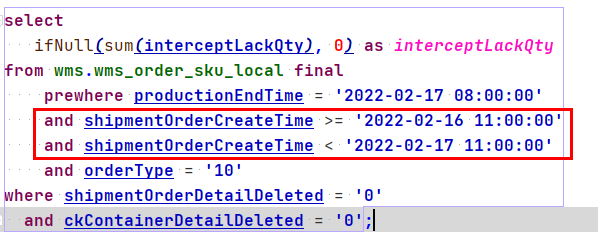
|
|
shipmentOrderCreateTime 为分区键,在添加这个条件后再看下效果。 |

|
|
|

|
|
通过分析日志可以看到没有使用主键索引,但是使用了分区索引,扫描分片数为 6,MarkRange 186,共扫描 1409001 行数据,使用内存 40.76MB,扫描数据大小等大幅度降低节省大量服务器资源,并且提升了查询速度,0.267s 降低到 0.18s。 9.2 建表优化9.2.1 尽量不使用 Nullable 类型 从实践上看,设置成 Nullable 对性能影响也没有多大,可能是因为我们数据量比较小。不过官方已经明确指出尽量不要使用 Nullable 类型,因为 Nullable 字段不能被索引,而且 Nullable 列除了有一个存储正常值的文件,还会有一个额外的文件来存储 Null 标记。 Using Nullable almost always negatively affects performance, keep this in mind when designing your databases. 上述建表语句为例,number 列会生成 number.null.* 两个额外文件,占用额外存储空间,而 orderNo 列则没有额外的 null 标识的存储文件。 |

|
|
我们实际应用中建表,难免会遇到这种可能为 null 的字段,这种情况下可以使用不可能出现的一个值作为默认值,例如将状态字段都是 0 及以上的值,那么可以设置为 - 1 为默认值,而不是使用 nullable。 9.2.2 分区粒度 分区粒度根据业务场景特性来设置,不宜过粗也不宜过细。我们的数据一般都是按照时间来严格划分,所以都是按天、按月来划分分区。如果索引粒度过细按分钟、按小时等划分会产生大量的分区目录,更不能直接 PARTITION BY create_time ,会导致分区数量惊人的多,几乎每条数据都有一个分区会严重的影响性能。如果索引粒度过粗,会导致单个分区的数据量级比较大,上面 7.2 节的问题和索引粒度也有关系,按月分区,单个分区数据量到达 500W 级,数据范围 1 号到 18 号,只查询 17 号,18 号两天的数据量,但是优化按月分区,分区合并之后不得不处理不相关的 1 号到 16 号的额外数据,如果按天分区就不会产生 CPU 飙升的现象。所以要根据自己业务特性来创建,保持一个原则就是查询只处理本次查询条件范围内的数据,不额外处理不相关的数据。 9.2.3 分布式表选择合适的分片规则 以上文 7.1 中为例,分布式表选择的分片规则不合理,导致数据倾斜严重落到了少数几个分片中。没有发挥出分布式数据库整个集群的计算能力,而是把压力全压在了少部分机器上。这样整体集群的性能肯定是上不来的,所以根据业务场景选择合适的分片规则,比如我们将 sipHash64 (warehouseNo) 优化为 sipHash64 (docId),其中 docId 是业务上唯一的一个标识。 9.3 性能测试,对比优化效果 在聊查询优化之前先说一个小工具,clickhouse 提供的一个 clickhouse-benchmark 性能测试工具,环境和前文提到的一样通过 docker 搭建 CK 环境,压测参数可参考官方文档,这里我举一个简单的单并发测试示例。 |

|
|
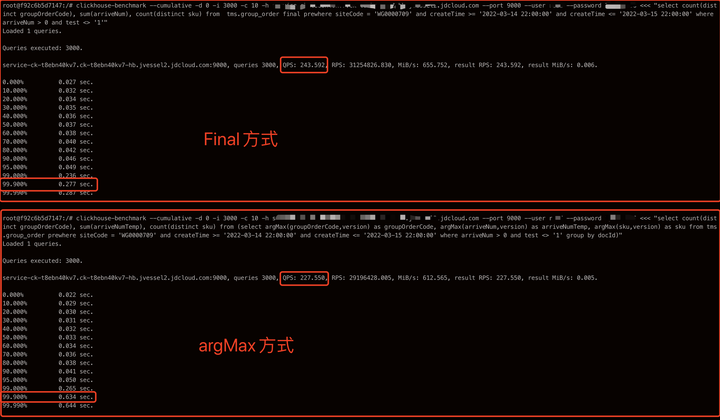
通过这种方式可以了解 SQL 级别的 QPS 和 TP99 等信息,这样就可以测试语句优化前后的性能差异。 9.4 查询优化9.4.1 条件聚合函数降低扫描数据行数 假设一个接口要统计某天的” 入库件量”,” 有效出库单量”,” 复核件量”。 一个接口出三个指标需要上述三个 SQL 语句查询 table_1 来完成,但是我们不难发现 dt 是一致的,区别在于 type 和 status 两个条件。假设 dt = ‘2021-01-1’ 每次查询需要扫描 100W 行数据,那么一次接口请求将会扫描 300W 行数据。通过条件聚合函数优化后将三次查询改成一次,那么扫描行数将降低为 100W 行,所以能极大的节省集群的计算资源。 条件聚合函数是比较灵活的,可根据自己业务情况自由发挥,记住一个宗旨就是减少整体的扫描量,就能到达提升查询性能的目的。 9.4.2 二级索引 MergeTree 系列的表引擎可以指定跳数索引。 跳数索引是指数据片段按照粒度 (建表时指定的 index_granularity) 分割成小块后,将 granularity_value 数量的小块组合成一个大的块,对这些大块写入索引信息,这样有助于使用 where 筛选时跳过大量不必要的数据,减少 SELECT 需要读取的数据量。 上例中的索引能让 ClickHouse 执行下面这些查询时减少读取数据量。 支持的索引类型 minmax:以 index granularity 为单位,存储指定表达式计算后的 min、max 值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少 IO。set (max_rows):以 index granularity 为单位,存储指定表达式的 distinct value 集合,用于快速判断等值查询是否命中该块,减少 IO。ngrambf_v1 (n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):将 string 进行 ngram 分词后,构建 bloom filter,能够优化等值、like、in 等查询条件。tokenbf_v1 (size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed): 与 ngrambf_v1 类似,区别是不使用 ngram 进行分词,而是通过标点符号进行词语分割。bloom_filter ([false_positive]):对指定列构建 bloom filter,用于加速等值、like、in 等查询条件的执行。 创建二级索引示例 重建分区索引数据:在创建二级索引前插入的数据,不能走二级索引,需要重建每个分区的索引数据后才能生效 9.4.3 final 替换 argMax 进行去重 对比下 final 和 argMax 两种方式的性能差距,如下 SQL |
|
|
final 方式的 TP99 明显要比 argMax 方式优秀很多 9.4.4 prewhere 替代 where ClickHouse 的语法支持了额外的 prewhere 过滤条件,它会先于 where 条件进行判断,可以看做是更高效率的 where,作用都是过滤数据。当在 sql 的 filter 条件中加上 prewhere 过滤条件时,存储扫描会分两阶段进行,先读取 prewhere 表达式中依赖的列值存储块,检查是否有记录满足条件,在把满足条件的其他列读出来,以下述的 SQL 为例,其中 prewhere 方式会优先扫描 type,dt 字段,将符合条件的列取出来,当没有任何记录满足条件时,其他列的数据就可以跳过不读了。相当于在 Mark Range 的基础上进一步缩小扫描范围。prewhere 相比 where 而言,处理的数据量会更少,性能会更高。看这段话可能不太容易理解, 上节我们说了使用 final 进行去重优化。通过 final 去重,并且使用 prewhere 进行查询条件优化时有个坑需要注意,prewhere 会优先于 final 进行执行,所以对于 status 这种值可变的字段处理过程中,能够查询到中间状态的数据行,导致最终数据不一致。 |

|
|
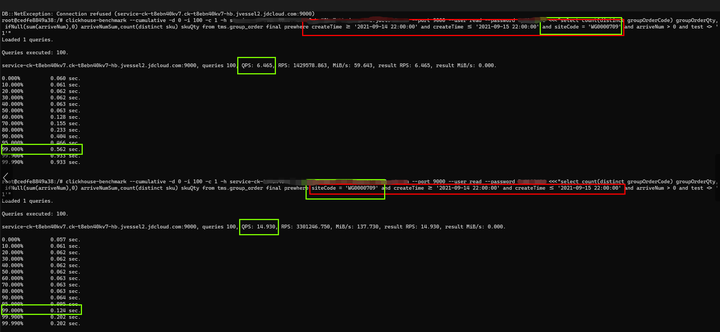
如上图所示,docId:123_1 的业务数据,进行三次写入,到 version=103 的数据是最新版本数据,当我们使用 where 过滤 status 这个可变值字段时,语句 1,语句 2 结果如下。 当我们引入 prewhere 后,语句 3 写法:prewhere 过滤 status 字段时将 status=1,version=102 的数据会过滤出来,导致我们查询结果不正确。正确的写法是语句 2,将不可变字段使用 prewhere 进行优化。 其他限制:prewhere 目前只能用于 MergeTree 系列的表引擎 9.4.5 列裁剪,分区裁剪 ClickHouse 非常适合存储大数据量的宽表,因此我们应该避免使用 SELECT * 操作,这是一个非常影响的操作。应当对列进行裁剪,只选择你需要的列,因为字段越少,消耗的 IO 资源就越少,从而性能就越高。 而分区裁剪就是只读取需要分区,控制好分区字段查询范围。 9.4.6 where、group by 顺序 where 和 group by 中的列顺序,要和建表语句中 order by 的列顺序统一,并且放在最前面使得它们有连续不间断的公共前缀,否则会影响查询性能。 建表语句 ORDER BY (siteCode, groupOrderCode, sku),语句 1 没有符合要求经过压测 QPS6.4,TP99 0.56s,语句 2 符合要求经过压测 QPS 14.9,TP99 0.12s |
|
|
10 如何抗住高并发、保证 ClickHouse 可用性 1)降低查询速度,提高吞吐量 max_threads:位于 users.xml 中,表示单个查询所能使用的最大 CPU 个数,默认是 CPU 核数,假如机器是 32C,则会起 32 个线程来处理当前请求。可以把 max_threads 调低,牺牲单次查询速度来保证 ClickHouse 的可用性,提升并发能力。可通过 jdbc 的 url 来配置 |

|
|
下图是基于 32C128G 配置,在保证 CK 集群能够提供稳定服务 CPU 使用率在 50% 的情况下针对 max_threads 做的一个压测,接口级别压测,一次请求执行 5 次 SQL,处理数据量 508W 行。可以看出 max_threads 越小,QPS 越优秀 TP99 越差。可根据自身业务情况来进行调整一个合适的配置值。 |

|
|
2)接口增加一定时间的缓存 3)异步任务执行查询语句,将聚合指标结果落到 ES 中,应用查询 ES 中的聚合结果 4)物化视图,通过预聚合方式解决这种问题,但是我们这种业务场景不适用 11 资料集合 ??建库、建表、创建二级索引等操作 ??更改 ORDER BY 字段,PARTITION BY,备份数据,单表迁移数据等操作 ??基于 docker 搭建 clickhouse-client 链接 ck 集群 ??基于 docker 搭建 grafana 监控 SQL 执行情况 ??test 环境自行搭建 clickhouse 作者:京东物流 马红岩 内容来源:京东云开发者社区 |
|
鉴于大家对于 ClickHouse以在存储数据超过20万亿行的情况下,在1秒内返回查询 这个性能的质疑,我这边更新贴上ClickHouse和各个公司测试和使用的一些文章,有兴趣的可以去看看,这个数据超过20万亿行的情况下,在1秒内返回查询,更多的是说明,ClickHouse的性能上限高,用来说明定性的,不是用于做定量的测试,如果大家对于定量的测试有兴趣的话,看看下面的测试和使用报告吧。 这个是ClickHouse官方的测试结果链接,会和各个主流的数据库做对比。 Performance comparison of database management systems (clickhouse.com) 下面国外各个公司使用的一些文章: Fast and Reliable Schema-Agnostic Log Analytics Platform - Uber Engineering Blog HTTP Analytics for 6M requests per second using ClickHouse (cloudflare.com) Our Online Analytical Processing Journey with ClickHouse on Kubernetes (ebayinc.com) https://bigdatadays.ru/wp-content/uploads/2019/10/D2-H3-3_Yakunin-Goihburg.pdf 国内的一些公司使用的文章: 唯品会基于Clickhouse的下一代日志系统技术揭秘_索引_存储_时间 (sohu.com) StarRocks VS ClickHouse,携程大住宿智能数据平台的应用_用户 (sohu.com) 最佳实践:微信 ClickHouse 实时数仓_数据_场景_业务 (sohu.com) ClickHouse神的地方在于,开辟了大数据查询速度优化的新思路,当然方法不是新的,但是整合了已经有的方式之后,得到的效果却特别的好。ClickHouse以在存储数据超过20万亿行的情况下,在1秒内返回查询,那它是怎么做到的?主要有下面的原因。 列式存储与数据压缩 列式存储和数据压缩,对于一款高性能数据库来说是必不可少的。如果你想让查询变得更快,那么最简单且有效的方法是减少数据扫描范围和数据传输时的大小,列式存储和数据压缩就可以做到这两点。 2. 向量化执行 能升级硬件解决的问题,千万别优化程序。能用钱解决的问题,那都不是问题。 向量化执行,可以简单地看作一项消除程序中循环的优化,是基于底层硬件实现的优化。这里用一个形象的例子比喻。小胡经营了一家果汁店,虽然店里的鲜榨苹果汁深受大家喜爱,但客户总是抱怨制作果汁的速度太慢。小胡的店里只有一台榨汁机,每次他都会从篮子里拿出一个苹果,放到榨汁机内等待出汁。如果有8个客户,每个客户都点了一杯苹果汁,那么小胡需要重复循环8次上述的榨汁流程,才能榨出8杯苹果汁。如果制作一杯果汁需要5分钟,那么全部制作完毕则需要40分钟。为了提升果汁的制作速度,小胡想出了一个办法。他将榨汁机的数量从1台增加到了8台,这么一来,他就可以从篮子里一次性拿出8个苹果,分别放入8台榨汁机同时榨汁。此时,小胡只需要5分钟就能够制作出8杯苹果汁。为了制作n杯果汁,非向量化执行的方式是用1台榨汁机重复循环制作n次,而向量化执行的方式是用n台榨汁机只执行1次。 |
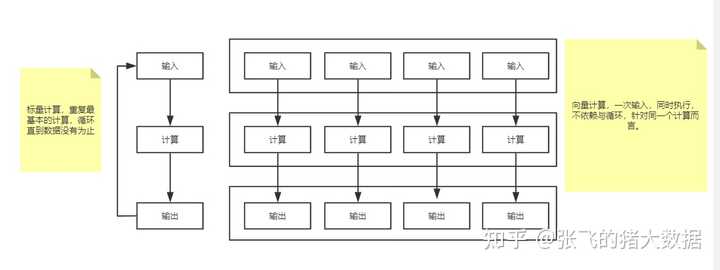
|
|
向量化执行 上图中,右侧为vectorization(向量化计算),左侧为经典的标量计算。将多次for循环计算变成一次计算完全仰仗于CPU的SIMD指令集,SIMD指令可以在一条cpu指令上处理2、4、8或者更多份的数据。在Intel处理器上,这个称之为SSE以及后来的AVX;在ARM处理器上,这个称之为NEON。 因此简单来说,向量化计算就是将一个loop――处理一个array的时候每次处理1个数据共处理N次,转化为vectorization――处理一个array的时候每次同时处理8个数据共处理N/4次,假如cpu指令上可以处理更多份的数据,设为M,那就是N/M次。 为了实现向量化执行,需要利用CPU的SIMD指令。SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据。现代计算机系统概念中,它是通过数据并行以提高性能的一种实现方式,它的原理是在CPU寄存器层面实现数据的并行操作。ClickHouse目前利用SSE4.2指令集实现向量化执行。 3. 多样化的表引擎 与MySQL类似,ClickHouse也将存储部分进行了抽象,把存储引擎作为一层独立的接口。目前ClickHouse共拥有合并树、内存、文件、接口和其他6大类20多种表引擎。每一种表引擎都有着各自的特点,用户可以根据实际业务场景的要求,选择合适的表引擎使用。 4. 多线程与分布式 多线程处理就是通过线程级并行的方式实现了性能的提升,ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。这种设计下,可以使得ClickHouse单条Query就能利用整机所有CPU,极致的并行处理能力,极大的降低了查询延时。 而分布式数据属于基于分而治之的基本思想,实现的优化,如果一台服务器性能吃紧,那么就利用多台服务的资源协同处理。这个前提是需要在数据层面实现数据的分布式,因为计算移动比数据移动更加划算,在各服务器之间,通过网络传输数据的成本是高昂的,所以预先将数据分布到各台服务器,将数据的计算查询直接下推到数据所在的服务器。 如果你对ClickHouse想了解更多,可以看看下面的文档和文章。 ClickHouse相关资料分享 参考资料: ClickHouse(01)什么是ClickHouse,ClickHouse适用于什么场景 - 知乎 (zhihu.com) ClickHouse(02)ClickHouse架构设计介绍概述与ClickHouse数据分片设计 - 知乎 (zhihu.com) ClickHouse(03)ClickHouse怎么安装和部署 - 知乎 (zhihu.com) ClickHouse(04)如何搭建ClickHouse集群 - 知乎 (zhihu.com) ClickHouse(05)ClickHouse数据类型详解 - 知乎 (zhihu.com) ClickHouse(06)ClickHouse建表语句DDL详细解析 |
|
你可能没有用过 ClickHouse ,但是一定听过它的名字。 |
|
|
为了拓展一下自己的知识面,前段时间,我找到了 《ClickHouse原理解析和应用实践》这本书来看。写的真心不错! 这篇回答我会简单从一个 ClickHouse 初学者的角度,给小伙伴们科普一下 OLAP、OLTP 以及 ClickHouse 的前世今生和应用场景。 个人能力有限。如果文章有任何需要补充/完善/修改的地方,欢迎在评论区指出,共同进步! OLAP 介绍 为了将企业的数据有效整合,快速制作出报表以供数据分析/决策使用,诞生了一个叫做 OLAP(Online Analytical Processing,联机分析处理)系统的概念,也叫做现代 BI(Business Intelligence,商业智能)系统。 |

|
|
与 OLAP 相对应的还有一个叫做 OLTP(Online Transaction Processing ,联机事务处理)的概念。这个我们平时日常接触的就比较多了,像企业的 ERP,CRM,OA 等系统都属于 OLTP 系统。 OLTP & OLAP 简单总结一下: OLTP : 可以保证操作的事务性,通常需要用到传统的关系型数据库比如 MySQL,主要操作是增删改查(比如添加用户、用户之间转账)。OLTP 通常处理的数据量不会很大,因为数据量大了之后 OLTP 数据库的响应一般会非常慢。OLAP : 对数据做分析然后得出一些结果比如数据报表,主要操作是查询(比如生成网站的流量分析报告)。OLAP 处理的数据量往往很大,并且 OLAP 处理的数据对象是数据仓库(data warehouse)中的数据。数据仓库 OLAP 系统一般以数据仓库作为基础。数据仓库是为了将分散的数据汇聚到一处,将它们统一存储起来。 |

|
|
数据仓库的构建通常还会涉及到 ETL 的过程。ETL 即数据抽取(Extract)、转换(Transform)、装载(Load)。 下面这张图片来自:What is a Data Warehouse? | IBM 大部分用于 OLTP 的数据库都可以执行 OLAP 相关的操作,只不过,效率通常都比较低,毕竟, 这不是它们所擅长的地方。 OLAP 分类 主流的 OLAP 可以分为 3 类 ROLAP、MOLAP、HOLAP。 ROLAP ( Relational OLAP,关系型 OLAP ) 对数据不进行预处理,实时聚合计算,灵活性更好!适用于 对查询模式不固定、查询灵活性要求高的场景。常见的 ROLAP 有 Presto,Impala,Clickhouse 等等。 MOLAP ( Multi-dimensional OLAP ,多维 OLAP) 会对数据预处理,这提高了查询性能,同时也降低了灵活性。 适用于查询场景相对固定并且对查询性能要求非常高的场景。常见的 MOLAP 有 Druid,Kylin,Doris 等等。 HOLAP ( Hybrid OLAP ,混合型 OLAP) 混合类型 OLAP。通常情况下,查询聚合性数据的时候,使用 MOLAP 技术;当查询明细数据时,使用 ROLAP 技术。在给定使用场景的前提下,以达到查询性能的最优化。 相关阅读推荐:《什么是 OLAP?主流八大开源 OLAP 技术架构对比》 ClickHouse简介 ClickHouse 是 Yandex(俄罗斯的一家做搜索引擎的公司)公司的一个产品,诞生于自家的在线流量分析产品―Yandex.Metrica。 |

|
|
根据 ClickHouse 官方文档介绍:ClickHouse 是一个用于联机分析(OLAP)的 MPP 架构的列式数据库管理系统(DBMS)。 目前的话,国内有很多公司都在使用 ClickHouse ,比如腾讯、字节、金数据、B 站。 下面是腾讯音乐对 ClickHouse 实践: |

|
|
Github 地址:https://github.com/ClickHouse/ClickHouse 。 |
|
|
前世今生 其实,ClickHouse 的诞生也是一步一步改进现有系统之后得到的产物! Yandex.Metrica 的第一版架构其实是基于 MySQL(ROLAP) 来做的。 后来,这一版架构出现了瓶颈,数据量过多(5800 亿)导致分析报告的耗费时间过长。即使对这一版架构进行了大量优化之后,耗费时间也仅仅是提高到了 26 秒。 于是,Yandex.Metrica 的研发团队开始另辟蹊径了! 他们自研了一个叫做 Metrage(MOLAP) 的新系统。Metrage 的架构设计和 MySQl 差别很大,就比如它使用的是 LSM 树作为索引结构而不是 B+ 树。 Metrage 虽然解决了性能问题,但是,产品方面又有了新的需求。 Metrage 只支持聚合数据查询,因此只有固定的报表分析功能,非常不灵活。我们希望可以有一个系统支持处理自定义报告这类。 于是,Yandex.Metrica 又自主研发出了 OLAPServer(HOLAP) 系统。并且,OLAPServer 使用 SQL 作为查询语言。 OLAPServer 系统专为非聚合数据使用,实时聚合性能非常强! 不过,OLAPServer 也有缺陷比如缺少对数据类型的支持(只支持一种数据类型)。并且,功能也比较简陋,仅仅支持一些简单的功能,并没有一个 DBMS 应该有的基本管理功能比如 DDL 查询。 于是,Yandex.Metrica 继续在 OLAPServer 的基础上进一步完善,最终打造出了 ClickHouse(ROLAP)。 为什么这么快? ClickHouse 官方给出了一份非常详细的 ClickHouse 性能测试图,并提供了和其他常见数据库的对比。 性能报告地址:https://clickhouse.tech/benchmark/dbms/ 。 通过这份报告,可以非常直观地感受到 ClickHouse 到底是有多快! |

|
|
这么说吧,ClickHouse在相同的服务器配置与数据量(1000万)下,平均响应速度是 MySQL 的400多倍,当数据量达到 1亿的话,平均响应速度是 MySQL 的800多倍。 不谈具体的技术与架构,ClickHouse 之所以能够这么快主要得益于下面几点(结合《ClickHouse 原理解析与应用实践》所做的总结): 特殊场景特殊对待 : 同一个场景的不同状况,选择使用不同的实现方式,尽可能将性能最大化。比如去重计数 uniqCombined() 函数,会根据数据量的不同选择不同的算法:当数据量较小的时候,会选择 Array 保存;当数据量中等的时候,会选择HashSet;而当数据量很大的时候,则使用 HyperLogLog 算法。勇于尝鲜,不行就换 : ClickHouse 会优先使用最合适、最快的算法。如果市面上出现了可能会更好用的新算法的话,ClickHouse 通常会立即将其纳入并进行验证。效果不错的话,就继续用着。效果不行的话,就直接踢掉。持续测试,持续改进 : 优秀的软件不是一朝一夕形成的,需要不断的测试改进。适用场景 ClickHouse 虽然性能很强,查询速度和 MySQL 这类关系型数据库完全不是一个量级。 但是,ClickHouse 并不可以取代 MySQL 这类关系型数据库,它们是互补的关系。 ClickHouse 作为一款 OLAP 数据库,其应用场景主要就是数据分析比如广告流量分析,不适用于 OLTP 事务性操作的场景,因为,它不支持事务并且对按行删除数据不够友好! 文章推荐 推荐一些不错的好文和书籍,方便大家继续深入学习。 中文 : OLAP 数仓入门问答-基础篇 (写的非常好 )秒级去重:ClickHouse 在腾讯海量游戏营销活动分析中的应用数据分析引擎黑马 ClickHouse 最新技术的实践与应用ClickHouse 在有赞的实践之路伴鱼事件分析平台:设计篇 :伴鱼的事件分析平台用到了 ClickHouse 来存储数据。ClickHouse 官方文档(中文版)漫谈 ClickHouse 在实时分析系统中的定位与作用 :《 ClickHouse 原理解析与应用实践》作者朱凯大佬的一次视频分享。 英文 : How ClickHouse saved our dataIntroducing ClickHouse -- The Fastest Data Warehouse You've Never Heard Of (Robert Hodges, Altinity) :油管上的一个视频。 我是 Guide哥,专注 Java 原创干货分享,大三开源JavaGuide ,目前已经 115k+ Star。 |

|
|
原创不易,欢迎点赞分享,欢迎关注 @JavaGuide,我会持续分享原创干货!加油,冲 |
|
下面给大家介绍一下 ClickHouse 年度最令人兴奋的五大新特性,分享者是来自【明源云】的 大数据平台首席专家 朱凯 老师。 演讲PPT:https://pan.baidu.com/s/10s7ZZJkvNCXgxUmx5DPzrA(提取码: 0000) 你将收益: 1.了解ClickHouse的全貌 2.ClickHouse在2021年的五大特征 ClickHouse的全貌1.为什么叫ClickHouse? ClickHouse的全称由两部分组成,第一个是Click Stream点击流,第二个是数据仓库Data Ware House,把这两个单词的一首一尾合起来就叫ClickHouse。如果大家很了解这个领域的话,只通过这个名字,就可以一眼看出它的初衷,ClickHouse最原本要去解决的问题是如何支撑基于点击流的数据仓库。 2.ClickHouse的发迹 ClickHouse最开始是从在Yandex发迹起来的。Yandex是一家来自俄罗斯的互联网公司,以搜索引擎起家,是俄国第一的搜索引擎。除了搜索引擎以外,还有50多种b2b和b2c的产品,体量很大。众所周知,搜索引擎的很大一部分营收是广告流量带来的,所以通常一家搜索引擎公司的背后都会伴生一个流量站点的分析网站。Yandex也有一个自己的流量站点分析工具平台,叫Metrica,它是现在全球第三大网络流量分析工具,每天处理超过30亿个事件,其中分析覆盖数百万网站,每天拥有超过10万分析师用户,而ClickHouse就是在背后去支撑这个平台运转的。 在2021年,ClickHouse的初创团队也独立成立了同名的商业化公司,并在9月获得了5000万美元的A轮投资,同年10月获得了2.5亿美元的B轮投资,公司聚焦在ClickHouse云服务上。 3. 显著特点 ①入门简单 是一款OLAP数据库,具备完整的DBMS功能,支持SQL,提供DDL、DML语句。以ROLAP模型为主,同时也支持 MOLAP(特殊的表引擎+物化视图),支持 Projection。 ②Everything is table 面向表编程,提供数十种表引擎,包含代理访问外部资源(例如Zookeeper,HDFS,文件等)。内置Mysql,PostgreSQL binlog监听。甚至贡献者名单也有专门一张表。 ③接口丰富 提供TCP、HTTP底层访问接口,提供JDBC、CLI等封装接口。 兼容 MySQL、Postgres 客户端 支持Java、Python、Nodejs等众多第三方接口,内置数百个函数。 ④在线查询 实时应答,无需预处理。也支持立方体预聚合。 ⑤分布式架构 MPP架构,支持集群模式,支持数据分区、分片、副本。 ⑥高性能 列存、高压缩、向量化引擎,秒杀一切的性能。单机部署,即拥有高性能。 ⑦安全可靠 熔断机制,防误删机制。 ⑧完善的权限系统 RBAC,客户端接入权限,资源访问权限,操作访问权限,数据行级权限。 ⑨开源软件,社区活跃 2016年开源,Apache-2.0协议。 850+ Contributors、21.1K+ Star 、4.1K Forks,发版速度和它的性能一样快。 2021年 Top 5 Feature 下面进入重点!!! 1. 利用JIT提升数十倍查询性能 ClickHouse同时使用了Vectorize query execution(向量化执行)和Runtime code generation(运行时代码生成)。ClickHouse被大家所熟知的是向量行化执行,除此之外,其实它也用到了代码生成技术,这部分的好处主要是有助于L1和L2缓存重用,更好地利用编译器的优化,其中包括更好地执行分支预测,更好地利用cpu指令集。 JIT,Just-In-Time,即时编译是一种Runtime code generation技术。ClickHouse利用JIT可以获得数倍到数十倍的性能提升。 |

|
|
上图是现在CPU架构中各级储存的耗时,L1,L2缓存相比于内存和磁盘有20倍到200倍的性能提升。如果我们能很好的利用L1,L2缓存命中,从硬件角度会有非常大的提升。 从21.6版本开始就可以使用这个新特性了。JIT的基准编译时间在15ms左右,随着代码增长它会线性增长。第一种是在select里面有的表达式运算,ClickHouse会利用JIT去提升性能,普遍有1.5到3倍提升,特殊情况下能达到20倍。第二种是在聚合函数阶段去优化,普遍也有1到2倍提升。 2. 支持基于Lambda的UDF ClickHouse已经从21.10版本就开始支持了基于Lambda的UDF。虽然不是一个直接的性能提升,但是从应用性角度来说,也是一个性能的提升。目前虽然这个udf相对来讲还比较简单,但其实也能解决很多问题了。 |

|
|
当前是基于一个Lambda表达式的方式去做这个自定义函数Create Function的方式去定义,用Lambda表达式去定义很多自定义函数,然后就可以在查询语句里面去调用。现在ClickHouse存储目录上面会多一个user_defined的数据文件夹,它会把所有的自定义的函数保存在里面。目前这个制定函数也支持嵌套去调用,比较方便。 3. 开窗函数 以前,ClickHouse没有原生的开窗函数,像一些传统数据库,包括hive里面都是有开窗函数的,从那些技术转过来可能会不方便。比如左图,以前要去写一个类似的开窗,可能写很多SQL,可能要用数组JOIN的方式,或者很多数组函数,实践起来很麻烦。从21.3版本以后,有了原生的开窗函数,包括分析函数都已经内置了。现在去在ClickHouse上面想做一些同比环比分析,会比以前方便很多。 |

|
|
4. 支持S3和HDFS存储的零拷贝复制 ClickHouse现在是云原生的,支持分层存储。如果你关注它,会看到它的一条演进轨迹。最开始是单机的,单机即可实现很多高性能查询;然后演进到分布式,利用了比如复制表、分布式表,巧妙地变成了一个分布式架构;再往后,大家在讲云原生,也是可以分层存储、存算分离,有一些存储可以放到S3上,也可以放到HDFS上面去;后来也支持了OSS,目前也是通过原生的分层存储方式向云原生再迈进了一步。在此之前,虽然ClickHouse支持把一些冷数据,或者是部分的数据放到像S3这样的对象存储上面去,但是它的实现比较粗暴。 |
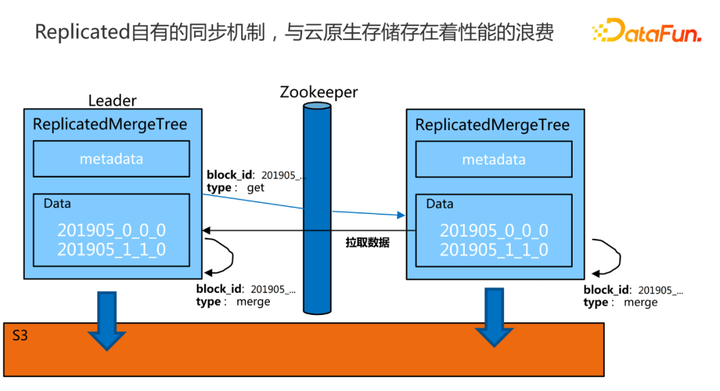
|
|
这里简单画了一个图,ClickHouse的副本机制其实是这样的一个过程。两个副本,有一个主副本是leader。当往这个副本去写入一些数据的时候,它在自己写完以后,会通过ZooKeeper去发布一些命令,比如写了左边的一个分区,下面data有比如201905这样一个分区写完了以后,它会通过ZooKeeper去发布一条命令给到另外一个副本,另外一个副本收到这个命令以后,是一个get类型的,就知道要去主副本拉数据,以实现这两个副本之间的同步。ClickHouse的从副本会通过ZooKeeper传递这个指令以后,点对点地直接去找这个Leader,从Leader下载这个分区的数据给到自己。这就是比较简单的,传统的ClickHouse的副本同步机制。目前ClickHouse把它的数据真正放到S3上去了以后,这里就会有一个冲突,S3自己内部已经处理好了数据之间的同步复制,但是这个replica也有一套同步机制, 这两套同步机制在同时运行,就存在着性能浪费,ClickHouse它自己就可以不用再同步了,只是做原数据同步,而把真正的数据同步就交给像S3这样的云原生就可以了。 |
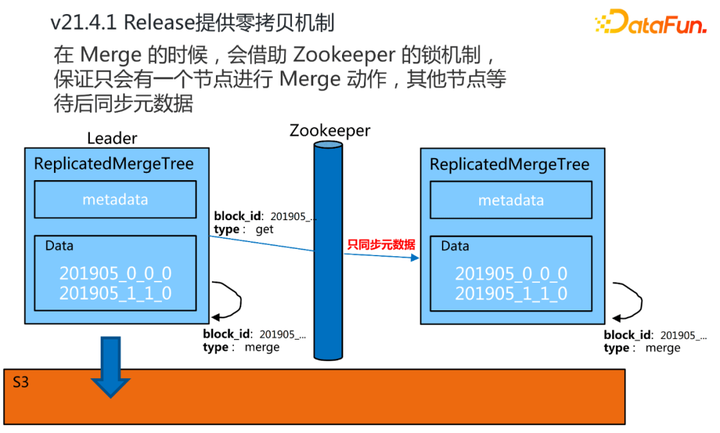
|
|
从21.4.1版本之后ClickHouse社区提供了这种零拷贝的机制。简单来讲就是ClickHouse只做元数据同步。在我们向某一个副本去写数据,或者是某一个副本在做合并的时候,它会借助ZooKeeper的锁机制,保证只有一个节点会去做这样的一个动作,然后其他的节点,不会去真正同步数据,或者去合并分区,只是作为一个元数据的同步,而把真正的数据之间的同步复制交给云存储本身。通过这样的一个零拷贝机制,去掉了无谓的性能开销。有了这个特性以后,ClickHouse的可用性变得更强了。 5. Projection Projection主要是解决了ClickHouse的两个痛点。 |
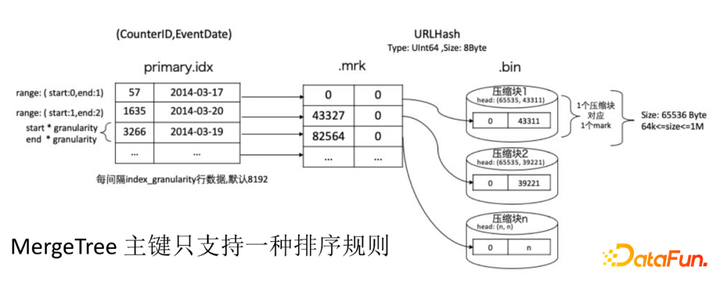
|
|
第一个痛点是,它的组件只支持一种排序规则。ClickHouse的索引架构是:首先我们通过建表的时候给它指定一个Order By键,它会通过这个排序键去建立稀疏索引,也就是primary.idx。这个稀疏索引是根据组件的排序规则来排序的,它会有一个映射文件以及对应的数据压缩块,通过这种方式去做查询加速。由于只有一种排序规则,如果在数据量很大的情况下,通过组件的这个顺序去做一些过滤和查询,性能是非常好的。但是查询业务往往是千变万化的,不可能所有的查询场景都是通过一套排序规则能把它覆盖到。如果查询的条件不是组件的顺序,那性能就会有所下降。 |
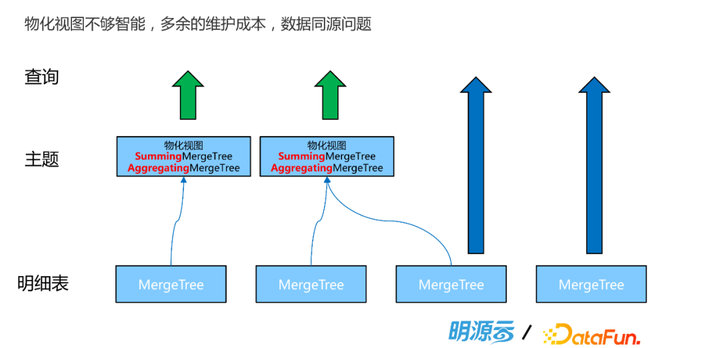
|
|
第二个痛点就是物化视图不是那么智能。我们面向一些特定的主题,也是可以利用物化视图。这是因为物化视图是有表引擎的,我们可以通过一些预聚合的表引擎去建Cube,然后让这些数据物化提升查询性能。这样一套架构也是传统数仓的做法,很多数据库也会通过这种物化视图去分层。但物化视图在ClickHouse里是独立的表,因此加上原表就有很多个表,维护成本会很高。而且由于不是同一张表,会存在数据从原表向物化视图的一个流向的过程,这时如果原表发生数据的删除、修改和更新,那么从数据质量的角度也可能存在问题。 为了解决这两个问题提出了Projection,简单来说可以理解成更加智能的物化视图。它有几个特点,第一是Part Level存储,ClickHouse有一张图会看到分区目录的物理布局,数据的物理布局是按分区目录去布局的。普通的物化视图是独立的一张表,而这个Projection是在分区级别,在一张表的分区里面有一个独立的存储,这是一个Part Level的存储。第二是正因为它和原表分区在一起,所以说它的数据是同源的。如果原表的数据变了,那么Projection也会发生变化。第三,Projection的使用是无感的,它更像是原表的一个智能的索引,在查询时会去自动匹配表。对一张表可以创建很多个Projection,查询时直接查这个原表,会根据算法去匹配这个Projection,如果能匹配上,就用一个最优的Projection提供查询加速,如果没有命中还是查原表。有了这个特性以后,会比使用物化视图方便非常多。 |

|
|
比如建一张MergeTree,可以看原表的排序是Order By 4个字段。如果基于这个顺序去查表,比如用CounterID去做条件,性能会很好,但如果换一个字段,比如用EventTime去查,性能就可能会下降。现在可以针对这个原表,去创建一个Projection,把想要的顺序写成一段select语句,即把想要查的列以及排序规则在这里面写好,那么它就会基于这个sql去创建一个Projection。这是在明细查询的角度,如果在聚合分析的角度也是可以的。比如想针对某个group by的场景,去做这种特定主题的加速,那么也创建一个这样的Projection就可以了。在后面查询的时候,就查原表,按sql去查。它只要能匹配上定义的这个sql的范围,就会通过Projection里面的数据去做查询返回,这样的性能将会有很大的提升。 |

|
|
上图就是表内文件存储结构。数据和索引文件会按照不同表不同Part去分隔,且在每个Part文件夹中又会包含许多个文件,其中有元数据(columns.txt),有列相关的索引和数据文件(Column.bin, Column.mrk2,Column.bin),主键索引(primary.idx)等。 右边是一个正常的Projection,和Part目录一一对应。每当我们给表创建Projection时,会在Part文件夹下创建子目录用于记录Projection信息。它和整张表共用同一份元数据,所以它自己是没有这个表的元数据的。然后它会通过一个motivation的异步操作,在分区下面去再生成一个子目录,这个子分区跟我们的分区是一样的。这个子目录存的就是基于一个新的索引的规则和预处理好的数据。当在查询中,能匹配到的Projection时,就会使用部分预处理好的数据直接返回,这也正是加速的本质。具备了这个武器以后,ClickHouse又变强了。比如上图左边是直接去查明细表,可以直接做实时查询,现在有了右边的Projection以后,但是查询速度提升了。但目前Projection不支持跨表,所以对于有跨表的预聚合的场景,还是要利用物化视图。Projection和物化视图可以搭配使用。 今天的分享就到这里,谢谢大家~ 下载更多学习资料、PPT,可以关注微信公众号「DataFunSummit」。 |
|
利益相关, StarRocks研发 clickhouse到底有哪些吊炸天的优化? 这个问题的答案,每年都修改一次, 以适配当下的反思和对CK的重新认识; 当初被CK的coding和技术细节所折服, 但时间久了以后,会对抽象泄露产生疲劳. 什么叫抽象泄露?就是特例优化,特例优化做得多,做得深,性能肯定好. 举几个例子: Support limit clause in array_agg function ・ Issue #36793 ・ StarRocks/starrocks[Optimization]Introduce a partial_apply_null method for Expr to short-circuit Join operators. ・ Issue #24570 ・ StarRocks/starrockshttps://github.com/StarRocks/starrocks/issues/36793 这种抽象泄露, 在熟悉代码前提下,结合业务场景, 稍作思考, 便可以想出很多个, 用不着参考其他系统, 而且coding的速度赶不上出idea的速度. |
|
|
| [收藏本文] 【下载本文】 |
| 人物音乐 最新文章 |
| 如何评价范进? |
| 如何评价安妮・海瑟薇? |
| 央视纪念视频选用巴桑原版《天路》,删掉韩 |
| 韩红的演唱水平在中国乐坛处于什么位置? |
| 如何评价《鸣潮》巡回演唱会「致予新世界」 |
| 为什么会有钢琴老师讲不带成人学生? |
| 为什么孙燕姿不招黑? |
| 2025年如何评价周深的歌唱实力和发展潜力? |
| 周林王陶四个人应该怎么排序? |
| 如果汪苏泷,许嵩和徐良,网络三巨头合体, |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
|
古典名著
名著精选
外国名著
儿童童话
武侠小说
名人传记
学习励志
诗词散文
经典故事
其它杂谈
小说文学 恐怖推理 感情生活 瓶邪 原创小说 小说 故事 鬼故事 微小说 文学 耽美 师生 内向 成功 潇湘溪苑 旧巷笙歌 花千骨 剑来 万相之王 深空彼岸 浅浅寂寞 yy小说吧 穿越小说 校园小说 武侠小说 言情小说 玄幻小说 经典语录 三国演义 西游记 红楼梦 水浒传 古诗 易经 后宫 鼠猫 美文 坏蛋 对联 读后感 文字吧 武动乾坤 遮天 凡人修仙传 吞噬星空 盗墓笔记 斗破苍穹 绝世唐门 龙王传说 诛仙 庶女有毒 哈利波特 雪中悍刀行 知否知否应是绿肥红瘦 极品家丁 龙族 玄界之门 莽荒纪 全职高手 心理罪 校花的贴身高手 美人为馅 三体 我欲封天 少年王 旧巷笙歌 花千骨 剑来 万相之王 深空彼岸 天阿降临 重生唐三 最强狂兵 邻家天使大人把我变成废人这事 顶级弃少 大奉打更人 剑道第一仙 一剑独尊 剑仙在此 渡劫之王 第九特区 不败战神 星门 圣墟 |
|
|
| 网站联系: qq:121756557 email:121756557@qq.com |