| |
|
|
|
| 阅读网 -> 明星艺术 -> 为什么 ViT 里的 image patch 要设计成不重叠? -> 正文阅读 |
|
|
[明星艺术]为什么 ViT 里的 image patch 要设计成不重叠? |
| [收藏本文] 【下载本文】 |
|
ViT里的image patch设计似乎有悖于过去对特征提取的理解,即context对于 representation encoding的作用。而在T… |
|
因为ViT有更大的野心,ViT的目的不是提出一个SOTA的模型,而是创建fundamental model。 引入卷积可以很简单,也可以很复杂。简单的在transformer之前放一个CNN,也可以像Swim/hiera一样借用CNN的思想。总之可以讨论的东西很多,也可以取得更好的结果,但更好的结果不意味着更大的贡献。假如有一个成功的工作A,你提出了一个新的工作B。那么A+B>A,能说明你提出了一个比A更好的模型,作出了更大的贡献么?怎么证明(A+B)中是B起到了决定性作用?又凭什么说你的工作不是排列组合罢了?所以说(B>A)的贡献是大于(A+B>A),哪怕B<A+B。不利于表示学习就对了,就是要挑战一下图像的软肋,才能证明ViT的优越性。好比前面有座山,如果你能沿着最陡的路直接往上爬都能到山顶,那随便换条路径爬不是轻而易举?所以ViT把模型设计中最难的部分解决了以后,各种改动都轻而易举。不妨这么想,假如最开始出现的是Conv+ViT,那么masking的难度是不是就增加了,MIM的研究反而被拖慢了。 我把16x16的无重叠patch叫做pixel tokens,对应的语义特征叫做semantic tokens。自然pixel tokens是没什么语义信息的,是不适合表示学习的。无论是分类任务,还是分割任务,我们需要的都只是语音信息。除了生成任务,似乎pixel tokens还真没啥用。只有把pixel tokens转换成semantic tokens才能体现出transformer的强大。 最近我也用了上述思路写了一篇论文,特地选用“错误的正样本”进行对比学习。让审稿人要么嘴巴张大大,直接accept,要么气急败坏 "this shit makes no sense"。拭目以待吧。 |
|
1.为了跟卷积区分开,看起来貌似有创新,其实仔细一想还是老东西(步长等于patch尺寸的卷积)。毕竟ViT宣扬自己是不使用卷积的纯Transformer架构,设计成重叠patch不就明摆着是卷积吗(这不是自己打自己脸,露馅了)。 2.ViT使用Transformer架构,需要输入序列,把图像切割成不重叠的patch序列比较直观,不会有任何的计算浪费(后续其实有重叠patch的魔改)。 3.受到传统视觉的启发。NLP中,使用BoW方法会忽略掉词在句子中的顺序,将词袋模型引入CV中,可将图像切割为patch,这样可以把图像变为不同patch拼接得到的结果。这里的patch可类比为句子中的单词,完整的图像则可类比为一个完整的句子。 4.self-attention可以将不同的patch信息融合,缓解切割带来的信息损失。当然ViT真实存在不同patch信息交互的问题,可能会出现类似空洞卷积的网格效应,这是后续需要进一步研究的点。 |
|
|
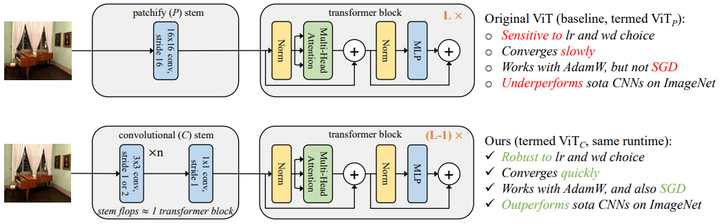
FAIR最新的文章Early Convolutions Help Transformers See Better证明了,用convolutional stem来替换patchify stem效果会更好,收敛更快。说明了ViT的无重叠patch拆分不是必须的。 陀飞轮:Convolutional stem is all you need! 探究ViT优化不稳定的本质原因156 赞同 ・ 19 评论文章 |
|
|
欢迎加入Smarter交流群,添加微信「cjy094617」,备注「学校-方向」即可 |
|
大概率是因为前深度学习时代就是这么玩的,在不重叠的16*16或者其他尺度的patch上提取斑点/角点然后编码。 随便搜一下sift,bow,fisher vector,vlad就差不多能理解了。 所以transformer本质还是提取局部特征+特征编码这套经典的不能再经典的视觉框架。 |
|
你的问题很专业,也非常关键,确实触及了 Vision Transformer (ViT) 的核心设计哲学和其对传统卷积神经网络 (CNN) 特征提取方式的颠覆性理解。为什么 ViT 中的 image patch 设计为不重叠?让我们从几个方面来分析: 1. 不重叠设计的理由:简化与效率优先 ViT 的设计初衷是将视觉任务转换为 NLP 任务的框架,这种跨领域的“移植”带来了截然不同的设计选择: (1) 简化计算负担: 不重叠的 patch 切割能够大大降低计算复杂度。如果我们使用重叠 patch,不仅需要提取更多的小区域,还会导致 Transformer 的输入序列长度增加,从而显著提高计算和内存需求。 举例来说,假如一个图片被切分为 16×1616 \times 1616×16 的 patch,使用不重叠切割会产生 N=HP×WPN = \frac{H}{P} \times \frac{W}{P}N=PH?×PW? 个 patch。如果采用重叠,每个 patch 可能需要在位置、数量上增长数倍,这会让自注意力机制的复杂度 (O(N2)O(N^2)O(N2)) 成为瓶颈。(2) 与 Transformer 架构的天然匹配: ViT 的设计基于 Transformer,这是一种全局关系建模的架构。每个 patch 会被看作一个独立的“token”,通过全局自注意力机制,Transformer 能捕获长距离的上下文信息。而 CNN 强调局部感受野,通过重叠卷积逐步累积上下文,但 Transformer 无需这样构建感受野,因为它天生擅长全局建模。2. Transformer 如何弥补不重叠的“劣势”? 确实,使用不重叠 patch 可能破坏物体的连续性和局部特征,但 ViT 通过以下方式弥补了这一点: (1) 自注意力机制弥补局部上下文的丢失在 ViT 中,虽然 patch 之间没有重叠,但自注意力机制允许任意两个 patch 直接交互。换句话说,即使邻近 patch 的边界被割裂,自注意力机制也可以通过学习捕获边界处的相关性。这种全局建模能力在理论上是比 CNN 的局部卷积更强的。(2) Patch 的大小选择至关重要ViT 通常使用较大的 patch(如 16×1616 \times 1616×16 或 32×3232 \times 3232×32),每个 patch 本质上已经包含了一个小的“局部感受野”。虽然这与 CNN 的小卷积核不完全一致,但相当于对图片进行了一个初步的降维编码,使模型在全局建模和局部细节保留之间取得平衡。如果 patch 太小,确实容易丢失局部结构;但如果 patch 适当增大,可能足够保留物体的基本信息。(3) 位置编码保留几何信息ViT 在输入序列中加入了位置编码,用来保留每个 patch 的相对位置关系。虽然 patch 不重叠,但位置编码让模型能够意识到某些 patch 是邻近的,从而补充了部分几何信息。这类似于 CNN 中通过卷积核捕获局部信息的方式。3. 为什么 ViT 不完全复制 CNN 的做法? CNN 和 ViT 的设计逻辑有本质差异,因此 ViT 不采用 CNN 的重叠卷积特性并非“疏漏”,而是更符合 Transformer 的核心架构: (1) CNN:从局部到全局CNN 是通过逐层堆叠卷积核,从局部感受野逐渐扩展到全局感受野。这种方式强调局部一致性(如边缘、纹理等),适合视觉任务。(2) ViT:从全局到局部ViT 的 Transformer 架构更注重全局建模,不依赖局部感受野的逐层累积。虽然起点是分割后的独立 patch,但自注意力机制能够弥补局部关系建模的不足。(3) 目标和任务的差异ViT 直接处理每个 patch 的特征表示,并将这些特征作为全局上下文的一部分来处理。与 CNN 强调逐步提取多层次特征不同,ViT 更像是一次性获取了全局信息,再通过 Transformer 层层细化特征。4. 重叠 patch 是否更优?混合模型的兴起 虽然 ViT 中采用了不重叠的 patch,但近年来的研究也在尝试结合 CNN 和 Transformer 的优点。例如: Swin Transformer:引入了滑动窗口的局部注意力机制,在局部上下文和全局建模之间取得平衡。Hybrid Models:将 CNN 用作前置特征提取器,将提取到的特征作为 Transformer 的输入,从而保留 CNN 的局部感受野优势。ConvNeXt 和 Focal Transformer:这些架构进一步研究了如何在局部卷积和全局注意力之间分配计算资源。 这些研究表明,重叠 patch 或局部注意力机制可能会在某些任务上更优,但其引入的计算开销需要权衡。 |
|
nlp里的input token是一个个单词,单词和单词之间是没有“重叠”这个概念的。transformer通过attention学习token之间的关系,因此可以说token是transformer中的可操作的最小单位。 vit在刚提出的时候就是照搬了nlp中的概念,image patch(也就是token)之间没有任何重叠。如果设计成可重叠的话,就相当于引入了局部相关性(inductive bias),等价于加强了local的attention 然而image patch和text的本质区别是:image patch本身也具有sementic,而且相邻patch是具有局部相关性的(比如说一个物体或者背景被切成了n个patch)。因此人为引入重叠可能会加速vit收敛,且不失其泛化能力 |
|
主要为了想说明是一个“纯的”非卷积网络吧。 实际上前面用两层CNN降采样然后再送到vit没准效果还能涨一点呢,反正asr是这样的(逃 |
|
vit 核心的数据内容 vit想法非常牛,但是数据处理的思想更牛,之前都没专门提出来过。 |
|
|
在对于一个图片,将一个图片分割成N块。巧妙的使用nn.Conv2d。 初始化 创建一个分块器和一个样本 输出分块的大小 数据再转换一下,image的embedding就完成了。 再向下推导,就是transformers了。没什么可介绍的了。 |
|
这个考虑确实是合理的。所以后面有很多增强的shifted token版本的patch emb。就是拿一个滑动窗口滑动一下我们最初的patch window然后加在一起。 不过由于Transformer过程中self Attention时每个token其实是有信息交换的,overlap的“冗余表征”有时候也没那么有必要,反而会带来一些过度的复杂性。 其实cnn的overlap也不是必须的。在yolov5还是v6的版本中,作者将stem设计成4x4,stride为4的non overlap kernel,也是借鉴了vit的处理方式。 个人觉得神经网络的设计没有一个范式,主要还是实验反馈设计。猜测神经网络的表达能力很多时候是过剩的,哪怕全连接也是过剩的。我们的设计只是不断地加入先验知识,改变参数空间,以让梯度下降优化器能够更好的优化这些参数。 固定优化算法(梯度下降加反向传播),调整模型结构取得了巨大成功,所以自然我们会沿着这条路径前进。但是说不定某天我们研究出了一个足够强的优化算法回头再看所有的模型设计都是一种过度设计hhhh |
|
因为深度学习没兴起之前,很多做压缩感知和稀疏编码的领域里面,也要对图像切patch,当时一些技术出发点认为是可以将图像的基本组成部分认为是图像patch而不是图像像素点,从而应用一系列的低秩稀疏字典学习稀疏编码等方法,transformer用图像patch加mlp其实和这种理解有些相似之处。 |
|
可以看看论文的实验分析部分,首先不设计成重叠是因为vision transformer 是由传统用于机器翻译的transformer中引申而来,在词向量中整个sequence在embedding过程中是没有重叠的。 至于你问的会不会影响信息的丢失? 首先self attention机制很好的考虑到了相邻patch之间的相关度,这里用李宏毅老师课程的一张图 |
|
|
不必担心他会丢失掉跨patch之间的信息。不丢掉跨patch之间的信息是不是就在一定程度上就意味着不需要重叠的设置。 为了达到语义分割等任务,需要像素级别的检测是不是就要把patch设置的越小? 首先作者明确给出了减小patch 的size会让我们计算的成本增加 |

|
|
然而计算成本增加了,小patch的效果是不是就比大patch的效果好? |
|
|
根据作者的实验来看,不可否认小patch优于大的patch,但如果只考虑减小patch就会让计算显著增加。考虑到现实情况,这显然不现实 |
|
因为没必要,也是比较简单的设计。后面的patch tokens会做self attention的,这意味着所有的patch tokens特征都会交互,所以最开始切分成不重叠的patch也没有关系。 "未来"的经典之作ViT:transformer is all you need!1745 赞同 ・ 68 评论文章 |
|
|
这里额外补充一点,ViT的图像的patch化,可以等价地用卷积来实现,比如patch size是2,可以用stride=2且卷积核为2x2的卷积实现,这也意味着每个2x2的patch是互相不重叠的。如果想有重叠,也可以用更大的卷积核,比如用stride=2且卷积核为3x3的卷积实现,那么相近的patch其实是有重合的。不过此时就需要对图像进行padding,这个会给不同位置的patch带来bias,相当于一种隐式的位置编码了。 其实这个问题,本身可能没有想象的那么复杂,最开始肯定考虑输入是pixel的,可是计算量承受不起,那就把图像分成patch。 |
|
因为重叠的是另外一篇文章,Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet https://arxiv.org/abs/2101.11986 |
|
感觉最初的设计者并没想这么多,就是直接简单的分块,也有可能重叠的块并不能带来提升甚至还会恶化,同时计算成本也会增加。不过依图开源的token to token VIT,在模型最开始部分分块的时候是重叠块,效果会比VIT好一些~ |
|
我觉得这里面可能并没有什么精妙的设计,很可能用重叠的 patch 用 vision transformer 依然是有效的。当然 vision transformer 的初衷是要尽可能的去掉人工的 inductive bias,因此从某种程度上来说就是要消除人为的特征提取,让模型从大量数据中自己学到特征提取的方法。 |
|
Inspired by the Transformer scaling successes in NLP, we experiment with applying a standard Transformer directly to images, with the fewest possible modifications. To do so, we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer. Image patches are treated the same way as tokens (words) in an NLP application. 作者就是为了减少改动,想directly,像tokens那样处理patches。 |
|
题主的concern是对的,切分-投影的做法确实很直接地兼容Transformer框架,不过这种方法确实有一定问题: 1、如果认为translation invariant是很重要的先验,那这种方法显然不满足这一性质; 2、对patch内部的空间结构信息有破坏,像素结构在上层(随着attention)逐渐丢失。 关于后一点,通过修改网络结构向Transformer block里补充像素结构已经被实验证实是有益的,例如华为诺亚实验室的TNT: |
|
设计成不重叠完全没问题,transformer的self-attention会对每个patch做attention,理论上每个patch之间都是有关联信号的,是个全局的信息,在局部在做重叠,信号可能就存在比较大的冗余了(swin transformer)。 |
|
VIT把图像切割成patch的方式,送去transformer做预测,个人理解其实和卷积卷积一样,只不过是把ViT是把卷积拉成了linear,我觉得题主问的这个问题很好,ViT的设计者可能是觉得重叠会导致patch的数量剧增,加大了计算量,还有一点原因,可能是它是先提出的,为了占坑,没考虑这么多。个人理解patch重叠是合理的,要不然swin transformer也不会被设计出来。 |
|
self-attention的输入输出大小是一致的,倘若出现重叠,那么重叠区域会在多个self-attention中出现,此时重叠区域的计算结果是应该取平均,还是取最后一次?这不太好决定,因此,不妨不重叠,一方面没有上述问题,一方面计算量也比较少,而且这和NLP里面token的意义似乎也更一致一点。 |
|
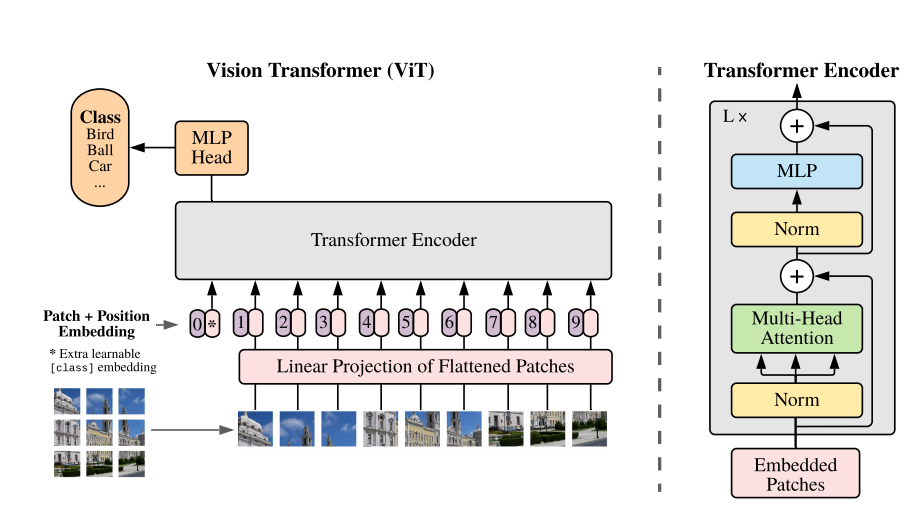
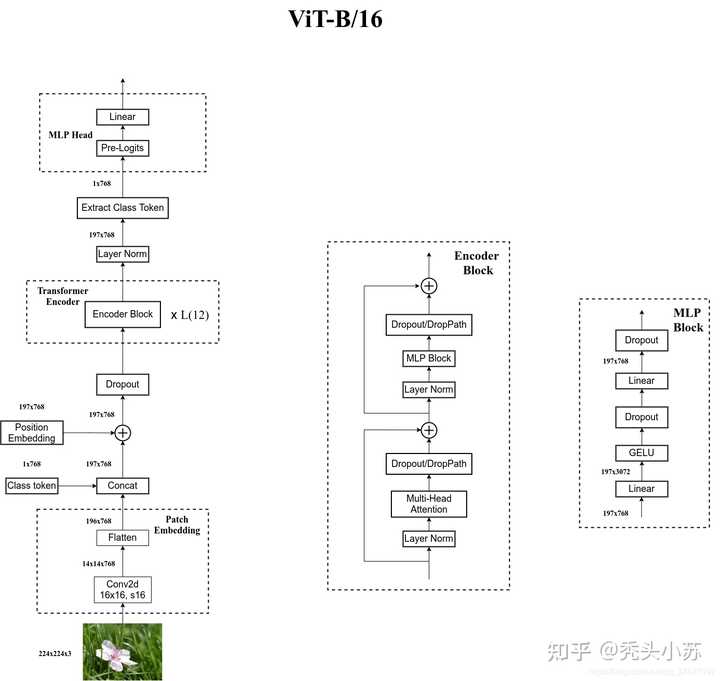
作者简介:秃头小苏,致力于用最通俗的语言描述问题 专栏推荐:深度学习网络原理与实战 近期目标:写好专栏的每一篇文章 支持小苏:点赞 、收藏?、留言 写在前面VIT模型构建VIT 训练脚本VIT分类任务实验结果小结 CV攻城狮入门VIT(vision transformer)之旅――VIT代码实战篇写在前面 ?? 在上一篇,我们已经介绍了VIT的原理,是不是发现还挺简单的呢!对VIT原理不清楚的请点击???了解详细。 那么这篇我将带大家一起来看看VIT的代码,主要为大家介绍VIT模型的搭建过程,也会简要的说说训练过程。 ?? 这篇VIT的模型是用于物体分类的,我们选择的例子是花的五分类问题。关于花的分类,我之前也有详细的介绍,是用卷积神经网络实现的,不清楚可以点击下列链接了解详情: 基于pytorch搭建AlexNet神经网络用于花类识别 基于pytorch搭建VGGNet神经网络用于花类识别 基于pytorch搭建GoogleNet神经网络用于花类识别 基于pytorch搭建ResNet神经网络用于花类识别 ?? 代码部分依旧参考的是B站霹雳吧啦Wz 的视频 ,强烈推荐大家观看喔,你一定会收获满满!!! 如果你看视频中有什么不理解的,可以来这篇文章寻找寻找答案喔。 ? 代码点击???获取。 VIT模型构建 ? 这部分我以VIT-Base模型为例为大家讲解,此模型的相关参数如下: ModelPatch sizeLayersHidden SizeMLP sizeHeadsParamsVIT-Base16*161276830721286M ?? 在上代码之前,我们有必要了解整个VIT模型的结构。关于这点我在上一篇VIT原理详解篇已经为大家介绍过,但上篇模型结构上的一些细节,像Droupout层,Encoder结构等等都是没有体现的,这些只有阅读源码才知道。下面给出整个VIT-Base模型的详细结构,如下图所示: |
|
|
vit-b/16 ? 图片来自于霹雳吧啦Wz 的博客 ?? 我们的代码是完全按照上图结构搭建的,但在解读代码之前我觉得很有必要再向大家强调一件事――「你看我上文推荐的视频或看我的代码解读都只起到一个辅助的作用,你很难说光靠看就能把这些理解透彻。我当时看视频的时候甚至很难完整的看完一遍,更多的还是靠自己一步一步的调试来看每个操作后维度的变换。」 ?? 我猜测可能有些同学还不是很清楚怎么在vit_model.py进行调试,其实很简单,只需要创建一个全1的tensor来模拟图片,将其当作输入输入网络即可,即可在vit_model.py文件末尾加上下列代码: ?? 那么下面我们就一步步的对代码进行解读,首先我们先对输入进行Patch_embedding操作,这部分我在理论详解篇有详细的介绍过,其就是采用一个卷积核大小为16*16,步长为16的卷积和一个展平操作实现的,相关代码如下: ?? 其实我觉得我再怎么解释这个代码的效果都不会很好,你只要在这里打上一个断点,这个过程就一目了然了。所以这篇文章可能就更倾向于让大家熟悉一下整个模型搭建的过程,具体细节大家可自行调试!!! ? 这步结束后,你会发现现在x的维度为(1,196,768)。其中1为batch_size数目,我们之前将其设为1。 |

|
|
image-20220814211716877 ? 接着我们会将此时的x和Class token拼接,相关代码如下: ? 同样可以来看看拼接后的维度,如下图: |

|
|
image-20220814213054360 ? 继续进行下一步――位置编码。位置编码是和上步得到的x进行相加的操作,相关代码如下: ?? 经过位置编码输入的维度并不会发生变换,如下: |

|
|
image-20220814224625559 ?? 位置编码过后,还会经过一个Dropout层,这并不会改变输入维度,相信大家对这个就很熟悉了,就不过多介绍了。 ? 到这里,我们的输入维度为(1,197,768)。接下来就要被送入encoder模块了。首先做了一个Layer Normalization归一化操作,接着会送入Multi-Head Attention部分,然后进行Droppath操作并做一个残差链接。这部分的代码如下: ? 相信你对Layer Normalization已经有相关了解了,不清楚的可以看我对Transfomer讲解的文章,里面有关于此部分的解释,这里不再重复叙述。但是你对Multi-Head Attention是如何实现的可能还存在诸多疑惑,此部代码如下: ? 光看确实难以发现其中的很多细节,那就尽情的调试吧!!! 这部分也不会改变x的尺寸,如下: |

|
|
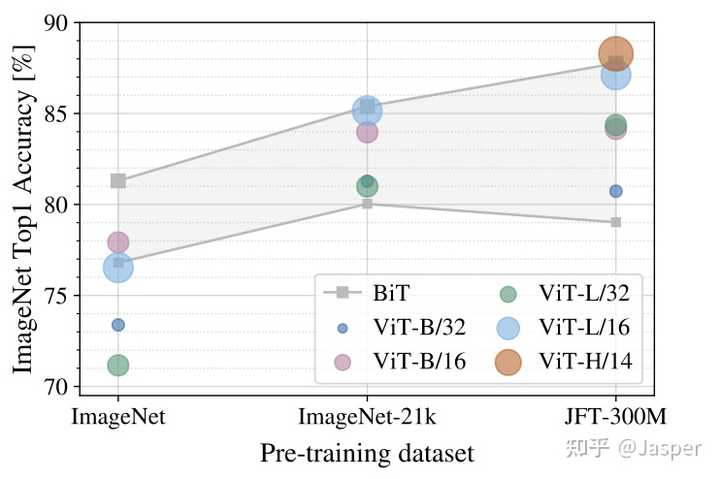
image-20220814232426884 ?? Multi-Head Attention后还有个Droppath层,其和Dropout类似,但说实话我也没了解过,就当成是一个固定的模块使用了。感兴趣的可以查阅资料。如果有很多人不了解或者我后期会经常用到这个函数的话,我也会出一期Dropout和Droppath区别的教程。这里就靠大家自己啦!!! ? 下一步同样是一个Layer Normalization层,接着是MLP Block,最后是一个Droppath加一个残差链接。这一部分还值得说的就是这个MLP Bolck了,但其实也非常简单,主要就是两个全连接层,相关代码如下: ?? 需要提醒大家的是上述代码的hidden_features其实就是一开始模型参数中MLP size,即3072。 ?? 这样一个encoder Block就介绍完了,接着只需要重复这个Block 12次即可。这部分相关代码如下: ? 注意输入输出这个encoder Block前后,x的维度同样没有发生变化,仍为(1,197,768)。接着会进行Layer Normalization操作。然后要通过切片的方式提取出Class Token,代码如下: ? 你会发现上述代码中会存在一个pre_logits()函数,这个函数其实就是一个全连接层加上一个Tanh激活函数,如下: ? 可以发现,这部分不是总存在的。当representation_size=None时,此部分只是一个恒等映射,即什么都不做。关于representation_size何时取何值,我这里做一个简要的说明。当我们的预训练数据集是ImageNet时,representation_size=None,即此时什么都不做;当预训练数据集为ImageNet-21k时,representation_size是一个特定的值,至于是多少是不定的,这和是Base、Large或Huge模型有关,我们这里以Base模型为例,representation_size=768。 ?? 经过pre_logits后,还有最后一个全连接层用于最终的分类。相关代码如下: ?? 到这里,VIT模型的搭建就全部介绍完啦,看到这里的话,为自己鼓个掌吧 VIT 训练脚本 ?? VIT训练部分和之前我用神经网络搭建的花类识别训练脚本基本是一样的,不清楚的可以先去看看之前的文章。这里我给大家讲讲怎么进行训练。其实你需要修改的地方只有两处,第一是数据集的路径,在代码中设置默认路径如下: ?? 我们只需要将"/data/flower_photos"修改成我们对应的数据集路径即可。「需要注意的是这里路径要指定到flower_photos文件夹,否则检测不到图片,这里和之前讲的还是有点差别的。」 ? 还有一处你需要修改的地方为预训练权重的位置,代码中默认路径如下: ? 我们需要将'./vit_base_patch16_224_in21k.pth'换成自己下载预训练权重的地址。「需要注意的时这里的预训练权重需要和你创建模型时选择的模型是一样的,即你选择了VIT_Base模型并在ImageNet21k上做预训练,你就要使用./vit_base_patch16_224_in21k.pth的预训练权重。」 ?? 最后我们训练的权重会保存在当前文件夹下的weights文件夹下,没有这个文件夹会创建一个新的,相关代码如下: VIT分类任务实验结果 ? 这里我们来看看花的五分类训练结果: ==不使用预训练模型训练10轮:== |

|
|
image-20220815111301706 ==不使用预训练权重训练50轮:== |

|
|
image-20220815111248735 ==使用预训练权重训练10轮:== |

|
|
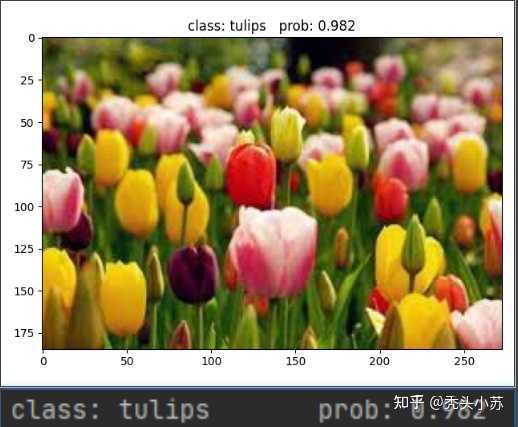
image-20220815111352563 ? 通过上面的三个实验你可以发现,VIT模型不使用预训练权重进行训练的话效果是非常差的,我们用ResNet网络不使用预训练权重训练50轮大概能达到0.79左右的准确率,而ViT只能达到0.561;但是使用了预训练模型的ResNet达到了0.915,而VIT高达0.971,效果是非常不错的。所以VIT是非常依赖预训练的,且预训练数据集越大,效果往往越好。 ? 最后我们来看看预测部分,下图为检测郁金香的概率: |
|
|
image-20220815112256243小结 ?? 到这里,VIT代码实战篇就介绍完了。同时CV攻城狮入门VIT(vision transformer)之旅的三篇文章到这里也就告一个段落了,希望大家能够有所收获吧!!! ?? 这里预告一下,后期我打算出Swin Transformer的教程,这个模型才是目前真正霸榜的存在,敬请期待吧!!! 如若文章对你有所帮助,那就 |

|
|
在这里插入图片描述 |
|
我试过重叠的,无论是vit分类还是dit生成,指标都会变好 所以这个问题没啥意义 |
|
简化模型结构与计算降低计算复杂度:不重叠的图像块划分方式可以使模型的计算更加简洁。每个图像块都是独立的,在进行后续的特征提取和处理时,不需要考虑相邻块之间的重叠部分的重复计算,大大降低了计算量,提高了模型的运行效率。便于模型构建:这种划分方式为模型的构建提供了清晰的结构。以规则的不重叠图像块为基础,可以更容易地设计和实现后续的 Transformer 模块,例如在进行多头注意力机制计算时,能够更直接地对每个图像块的特征进行处理,避免了因重叠带来的复杂索引和计算。 符合 Transformer 的输入假设独立性假设:Transformer 模型在处理序列数据时,假设每个元素都是相对独立的,虽然图像中的像素之间存在一定的空间相关性,但将图像划分为不重叠的块后,可以在一定程度上近似满足这种独立性假设。每个图像块可以看作是一个独立的 “单词” 或 “标记”,Transformer 可以基于这些独立的块来学习图像的全局特征和语义信息。位置编码的有效性:不重叠的图像块使得位置编码的设计和应用更加有效。位置编码用于给模型提供每个图像块在图像中的位置信息,由于图像块不重叠,位置编码能够更准确地反映每个块的空间位置,帮助模型更好地理解图像的结构和内容,从而更有效地学习到不同位置图像块之间的关系。 避免信息冗余减少重复信息:重叠的图像块会导致相邻块之间存在大量的重复信息,这不仅会增加模型的训练负担,还可能导致模型在学习过程中过度关注这些冗余信息,而忽略了更重要的特征。不重叠的设计可以确保每个图像块都提供独特的信息,使模型能够更高效地学习到图像的各种特征。提高特征学习效率:通过避免信息冗余,模型可以更专注于学习不同图像块所代表的不同特征,提高特征学习的效率。每个图像块都能够捕捉到图像中特定区域的独特信息,有助于模型更全面地理解图像内容,从而提升模型的性能。 |
|
信不信,设计成重叠的,计算量爆炸 |
|
|
| [收藏本文] 【下载本文】 |
| 明星艺术 最新文章 |
| 是不是欧美美术馆基本没有俄国画家的作品? |
| 为什么我的画线条那么乱,怎么样才能使线条 |
| 马克笔是不是永远也擦不掉? |
| 有人见过武则天的画像吗,非常好奇? |
| 郭德纲和曹云金决裂的真正原因是什么? |
| 如何评价范小勤的这幅字? |
| 如何评价脱口秀演员吐提古丽热杰打拳? |
| 为什么武侠里没人写皇上才是真的武林高手? |
| 穿着舞蹈服出门很奇怪吗? |
| 可以送一张你随手拍的照片吗? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
|
古典名著
名著精选
外国名著
儿童童话
武侠小说
名人传记
学习励志
诗词散文
经典故事
其它杂谈
小说文学 恐怖推理 感情生活 瓶邪 原创小说 小说 故事 鬼故事 微小说 文学 耽美 师生 内向 成功 潇湘溪苑 旧巷笙歌 花千骨 剑来 万相之王 深空彼岸 浅浅寂寞 yy小说吧 穿越小说 校园小说 武侠小说 言情小说 玄幻小说 经典语录 三国演义 西游记 红楼梦 水浒传 古诗 易经 后宫 鼠猫 美文 坏蛋 对联 读后感 文字吧 武动乾坤 遮天 凡人修仙传 吞噬星空 盗墓笔记 斗破苍穹 绝世唐门 龙王传说 诛仙 庶女有毒 哈利波特 雪中悍刀行 知否知否应是绿肥红瘦 极品家丁 龙族 玄界之门 莽荒纪 全职高手 心理罪 校花的贴身高手 美人为馅 三体 我欲封天 少年王 旧巷笙歌 花千骨 剑来 万相之王 深空彼岸 天阿降临 重生唐三 最强狂兵 邻家天使大人把我变成废人这事 顶级弃少 大奉打更人 剑道第一仙 一剑独尊 剑仙在此 渡劫之王 第九特区 不败战神 星门 圣墟 |
|
|
| 网站联系: qq:121756557 email:121756557@qq.com |