| |
|
|
| �Ķ��� -> �������� -> �ò������ֵ��˿��ߵ��ĺ��֣�������������ԣ� -> �����Ķ� |
|
|
[��������]�ò������ֵ��˿��ߵ��ĺ��֣�������������ԣ� |
| [�ղر���] �����ر��ġ� |
|
��Ȼ��ȫ����ʶ���֣������ܴ������Ƕ����ж��� |
|
��Ӱ����עһ���������ʹ���˵ߵ���������֣��ƺ�û�����˿������Ծ��� |

|
|
��ʱ�����ҷ�ת����ʱ�����µߵ���Ҳ��ʱ���ۡ� ������ͬһ�����ϣ�ǰ���ǵߵ�����ģ�������ɢװ�����ģ�����կ���֣���Ҳ�кܶ���û������������ȫ��ͬ���֡� |

|
|
|

|
|
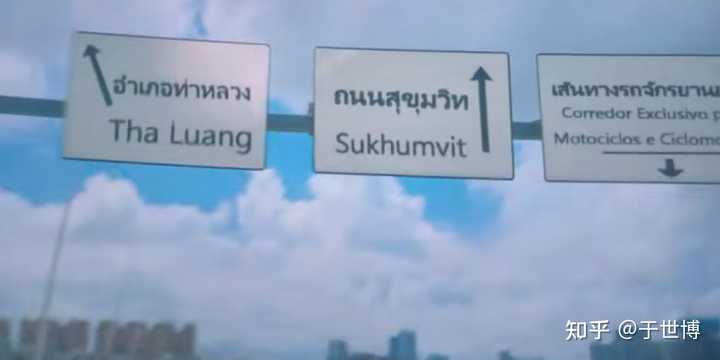
·�ϵĺܶ�·�ƣ��ֱ����̩�� |
|
|
������ڴ���ɢװ������ĸ������д����������/�����������ԭ�Ͳ�ֻ��϶����ǣ����ð��������ȥ���� |

|
|
�������ǰ��̩��ȥ����������ʱʵ�ĵ�����ģ�����ȦȦ���̩�ķ�һ��Ӧ�úܺ��ϰɣ���͵���Ū���˾��У� |

|
|
|

|
|
��˵��ЩȦȦ���������������Ϥ�����ܷ���������ߵ����� ���ں��֣�����ÿ���ֶ��ɵ���д����ȫû�Ӵ�������ͨ��Ҳ�����������ʲô��Ť�� ��ֻ�DZʻ������ȼ���ķ�����ѡ� �������� ��Ȼ��ô���ޣ�����û�ᡶ��ʧ���������������צ����̩��Ӳ������һ������ӡ� |
|
���ߤȤȤäƤʤˣ� |

|
|
ͼƬϵ���繣ת�أ�ԭʼ�������� |
|
����������һ�£�һ��8��ͬ�£�����Ӣ��֮�⣬�������������һ����ӡ�������5�˻�ŷ��һЩ�������ԡ� ����ǻᰢ�������ӡ�����ͬ��ȫ�ֱܷ�ߵ������壬����ŷ�˲��ܡ�������ɺ�����ȫ����ʾ���ѷֱ档 ����һ��ԭ���Ǵ���дϰ���Ʋ�ģ���/ӡ��˵���������ܿ����ʷ棬���²³��ʻ���ֹ��������ҵ���ȷ�ij����Ǻ���ȫ����ϸһ�¾�ץϹ�ˡ�����ŷ����˵û��������ȫ���ǻ�ͼ�ˣ����Բ��ֱܷ档 |
|
�Ҳ��룬����������йأ� |

|
|
|
|
�������ɣ�ż�����ڵ��������Ͽ������µߵ������Ҿ�������ģ��ɼ������װ����ӡ�����˻�û���֡��������Լ���Ϊ��Сϲ��������Щİ�������ֿ�����ʹ����һ��������ĸҲ����ʶ��ʱ��Ҳ��һ�۷��ַ��ˡ� ���Դ𰸴���ǣ�ȡ��������������ֵ����Ƿ�Ӵ����㹻�������ĺ��ֲ�������۲���� |
|
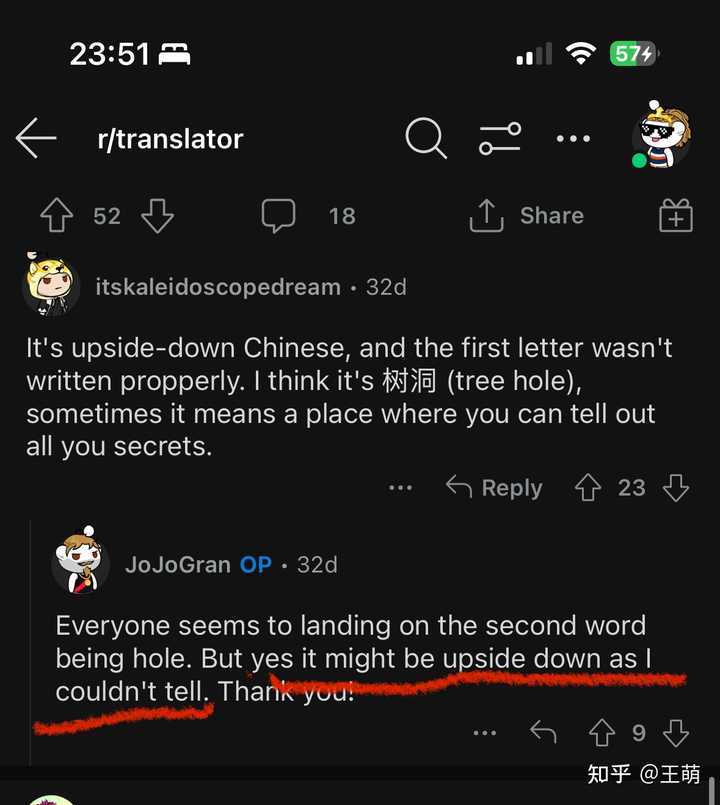
Reddit ���и���������ȶ���С�飩���� r/translator ���������˷������м���������Ѱ����ġ���������ʱ�ܼ������˷��ߵ������ģ����磺 |

|
|
|
|
|
�����Լ�Ҳ�������ֱ��Ƿ��ǵ������ġ� ��Ȼ�����淢�����Ĵ�����������ģ�������Ϊ�ܶ�ʱ�������������ж����������籭���ϵ����ġ��·��ϵ����ġ�·���ϵ����ġ���ͼ������ģ���������������һ����ֽƬ�Ͳ������жϡ� |
|
��ô�����������ͼ��������������Ļ��ǵ����ģ� |
|
|
|

|
|
|

|
|
|
���ͳ���һ���ľ��������磬���ܲ�������ԡ����ֵ���ȷ�ʸߴ� 93%�����һ���ж�����֣������֪�ܷdz��ɿ����ж��ˡ����������������������� 32 x 32 ��ͼƬ���ֳ� 6 �ࡪ�������֡��������Ҿ��ߵ������¾���ࡣ ѵ���������� Skia �ͷdz������壨�������źڣ����� Unicode ������ 0X4e00 �� 0X9fff�������������֡������䣩�ĺ��֣�����С���ȵ������ƽ�ơ����ź���ת�任���ٴ�ӡ��λͼ���ɵġ� ѭ�����ɣ��Ž��б�� ѵ����ʱ������ 10 ���Ӿ������ˡ� ��������չ���ĺ��ֲ��ԣ��һ��û�ͼ����һЩ�����ں��֣������������ࣨ> 90%������ȷ�жϡ����Ҷ�ѵ����δ���ֹ��������壨�����dz������壩Ҳ�ȶ��� ���˵����ֻҪ֪����ȷ����ĺ��ּ��Ŷ��ˣ������ж�������û�еߵ������������������֪��֪�����ֵĺ�����û��ϵ�ġ�Ҳ����Ҫ���⺺�ֵ����ַ��� ��Ϊ���ֻ࣬Ҫ����С�����������֣������ײ�������ɡ���ʹ����İ�����ԣ�Ҳ���жϳ���û�еߵ��� �Ը����ᵽ�������ֿ��������жϵ�����Ҳ�������Ʋ��ԡ�����뺺�ĵ�������ơ������ĺ��Ѱ��պ��������������ֹ������µĺ��������ԡ���������ϸ����ǰ����˵���������Ǽǵ����⼸���̶����Σ�����ϰ����ij�ֹ��ɡ� ����������ͨ����һ�����ֵ�������ȥ�ж���һ�����ֵ�ͼƬ����������IJ�ͬ�����ּ��Ƿ����ij�����������µĹ�ͬ��������Ŀǰ�����Ƿġ��п��ٿ��� |

|
|
|

|
|
��Ҷ������������Ҵ�֪����ĵط�������ͼ |
|
�����������ԣ� ��������ʮ����ǰ�ײ���� ��ʱ������ת90���������д��ë���֣� ���������ô��ˣ� ��˵��һ���ġ���үүд���־���ȫ����õġ�����д��Ҳ�� �������������������������������������������� ����ͻȻ��ʶ������ת90�������Ϊ�˴������д���Ķ�Ч���� �Ͼ�����һ�ο���үүд���֣�������д�ġ� |
|
ͼƬ�����ڷ�����������ֻ��� |

|
|
|

|
|
�����IJ���������һ�ģ����������Ĵ����Ӷ������� |
|
˾ĸ�춦 ��˵���������ĵ��ˣ�����ר�ҿ���Ҳһ������������� |
|
��Щ�������ᆳ���������÷��ˡ��һ��ڹ��ڼ����Ѱ���д���˵ġ���ȫ����ʶ��ȷʵ�ֲ������� |
|
����������Сѧʱ��ͬѧ������С˵���Ҿ��������Ķ��淴�ſ�����Ȼ���ñ����죬Ҫͣ�������������˷�ҳ�� |
|
Ӧ�ò��ܡ� �и��Ƚϻ���й����ڷ���up������һ���Ǹ����������;�ˮ�������������������ӭ������д�ġ��з���������ǵ��ŵġ�����ͼ |

|
|
ע����� ���Դ���Dz��ܡ� ��������˳������ȷ�ģ��Ҳ²⣬�������Dz�����ǰ�����õģ��Ͼ���һ����ͨ���ԭʼ�������䣬���ܺ����ҵ�һ����������ĵط�������ܵ�����ǣ�������ǰ��������Ӣ�������������ǵ����˸��ҷ��ˡ� ��Ƶ��ַ������������ˣ�������ô���ˮ�����źȣ�����������ֱ��Ҫ����_��������_bilibili |
|
���������������·�ת�IJ��ġ����Ҿ���IJ��ġ�����IJ��ġ����ġ����ġ��ɹ��ġ����ҡ�������Ĵ���ɶ��˼����������һ����ϣ�����ġ� |

|
|
�ܣ�����ż�����ܡ� �����йء� |
|
�B?uo?? ?u????u? p??????p ?��u?? I |
|
�������� ��ʵ�ö����ֵ��˿��ߵ��ĺ���Ҳ��һ���������� |

|
|
|
|
�������һ���Ҵ���û�������������������ж���ȷ����д�����һ�������ķ����� ���Ÿ���������ã�����дһ�£�Ȼ�����˳�ֵķ�����ȷ���� |
|
�п��ܿ��Ըо��������Dz����� ʮ����ǰ���ڹ����ʱ�������˽�����������⣬������ʶ��������ô������ ������2�� ����ر�����������������������������ڳ�ƪ���֣�һ���DZʻ�����һ���DZ��λ�ÿ������ж� |
|
�����Ӣ�ġ��� hallo��I like the whole word. But I love my mianland most. �������Ӣ�ģ�����ܿ��������м��������أ� �Ͻ���ͦͨ˳���ǡ� �ر��dz���Ա���ѣ�����Dz��Ǻ���Ϥ��Ц���� |

|
|
|
|
���ᣬ���Ҽ��Ÿ�³���������������Ŀ������Լ��ܲ��ֳܷ�������������������������֡� |
|
��Ȼ��������ϣ����Ϊ���� @��ȸ�� ���� OLE�ǡ����������Ƿ���������??O���ǡ�褡��� AZE�ǡ�֯�����������ǡ�?Z?�������顱�� ��ȻB??������ô��ת��ת�����ǡ������� ����EX?������ô��ת��ת���������Сд?x?�ٷ�ת��ת��Ҳֻ���ǡ��ڡ��� |
|
���˿��ԣ������Ǻܽ���Э���Ե� �����е��˲��� |

|
|
�����ϴο���������ȥ����ҽ�� �������ȥ���������ݸ�Ŀ������Dz�ͼ�� �������������棬�������ʱ����һ�㶼������Ц����һ����ͳ��¶� �õ����Ժ��������о���ô���� �о����Ժ��Ȼ�����õ��� �������ǿ�����ĵ��棬������ӡ�б�۵İ��������֣��Ÿ�������ô������ �˺��˶��Dz�ͬ�ģ���������û��һ�Ŷ��� ��ֻ��˵���˿��ԣ����˲��� |
|
��˵�ߵ������ˣ����������ģ����Ƕ����ϳɺ��֡� |

|
|
|
|
�п��ܣ��Ӿ���ġ��������ij̶ȶ����������ȫû�������֣���Ӧ��������ߵ��ĺ��֡����������һЩ���֣����ܲ���ʶ��Ҳ�п����Ծ����Ծ���ѧϰ�����ֹ����һЩģʽ���п��ܲ�����ߵ��ĺ��֣������ĺ���Խ�࣬Խ�п��ܲ���� |
|
�����ݼ����и����ã�����࣬��С�Ͱ�ͿͿ��������Ϊ����Ϳǽ�ϣ����˳ɾ��Ĵ�ֽ��һ��ʼ����ͦ���㣬����Խ��Խ�࣬Խ��Խ�������Ӳ�ǻ�������������������Ҫ���˴����ﱧ�����̿��ڵ��Ϻú��������͡�̫�����ˡ� ����һ�ϼƣ�˵������ֶ�ͯ����ɣ���Сʱ���Ҷ�������ֵĸ��棬������ɫ����ޱȣ���ʲô���������ģ�����С���ӵ��ξ�������Ҫ���ǣ����갴һ�¾�����ˣ���Ҳ�Ҳ������ˡ� ����֮�������ݰ����͵����������н��ѣ���Ҳ��ż�����͡���һ��ȥ�Է��������Ż��尤��������дд��������������һ�����Ÿ�ɤ���������ڻ�ʲô�أ�������һ�桪�� ������ȫֻ���߸���ʽ��С��֮�䣬�ҿ�����һ�ž���ߵ������İ��������֡� �º��ҹ۲���ü��Σ�������ȷ��������д�������ʶ��û�У��������ڡ�8��������ϣ���ͬ�������д��&����״̬�����������������ֻ��һ������Ȥ�ķ���ͼ�����������ֵ��˿������ִ��ҲӦ���ǡ� |
|
��Ȼ��ȫ����ʶ���֣������ܴ������Ƕ����ж��� ��Ȼ˵�������Ƕȣ����Ҿ�Ҫ�ͳ�����ߺ�����������ѧ����Ƭ�Ľ�ͼ�ˣ� |

|
|
ֻ���˸���ͷ��Ӧ��ûʲô���ܹ���Ķ��������ɣ� ע�⿴��ͷ���Ϸ��Ĺһ��� |

|
|
��÷�������������֣���ô����ô���Ƿ��ģ�Ȼ��������ô��ǿ�ع���ȥ�ˡ� �Ա�һ���ұ߲���ǽ������ȷ����ҵ���һ������ |

|
|
����˵�����´������Ƕȶ��ԣ��������ֵ��˿��ߵ��ĺ��������п��ܾ��첻�����⡣ ��Ȼ��Ҳ��û��Ӱ�쵽�˹���ߺ�����������ѧ����Ƭ�����ʦ�ǽ��и�����ѧ�����ʾ����ѧ����Ϊ����ȥ������ |
|
|
| [�ղر���] �����ر��ġ� |
| �������� �������� |
| ����������Ĺ⣿ |
| ���ʾ���Ȧ����кܶ������ |
| ���¸ٵ�ʱΪʲô��ô���غ���ΰ�� |
| ֪��Ŀǰ��ȱ�������������� emoji ������� |
| Ϊʲô�����������õ�ʱ��û�в����й� |
| ������ۺ��ͺ�����Ӱ����һ�Ƚ���Ʒ�� AI |
| Ϊʲô�Ҿ���AI�滭��ȫ���治�˻�ʦ�� |
| ������� 2024 �����괺����������Խ���ݵ� |
| ����˵��ճ�������ʲô���ģ� |
| ��ô��һ������ϲ���Ĵ����� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
|
�ŵ�����
������ѡ
�������
��ͯͯ��
����С˵
���˴���
ѧϰ��־
ʫ��ɢ��
�������
������̸
С˵��ѧ �ֲ����� �������� ƿа ԭ��С˵ С˵ ���� ������ С˵ ��ѧ ���� ʦ�� ���� �ɹ� ����ϪԷ �����ϸ� ��ǧ�� ���� ����֮�� ��ձ˰� dzdz��į yyС˵�� ��ԽС˵ УС˵ ����С˵ ����С˵ ����С˵ ������¼ �������� ���μ� ��¥�� ˮ䰴� ��ʫ �� �� ��è ���� ���� ���� ����� ���ְ� �䶯Ǭ�� ���� �������ɴ� �����ǿ� ��Ĺ�ʼ� ���Ʋ�� �������� ������˵ ���� ��Ů�ж� �������� ѩ�к����� ֪��֪��Ӧ���̷ʺ��� ��Ʒ�Ҷ� ���� ����֮�� ç�ļ� ȫְ���� ������ У������������ ����Ϊ�� ���� �������� ������ �����ϸ� ��ǧ�� ���� ����֮�� ��ձ˰� �찢���� �������� ��ǿ��� �ڼ���ʹ���˰��ұ�ɷ������� �������� ������� ������һ�� һ������ �����ڴ� �ɽ�֮�� �ھ����� ����ս�� ���� ʥ�� |
|
|
| ��վ��ϵ: qq:121756557 email:121756557@qq.com |