| |
|
|
| дФЖСЭј -> НЬг§аХЯЂ -> ШчКЮЦРМлФЯОЉДѓбЇжмжОЛЊНЬЪкЭХЖгНќШеЙЙНЈЕФББкЄЮыЃЈBeimingwuЃЉ? -> е§ЮФдФЖС |
|
|
[НЬг§аХЯЂ]ШчКЮЦРМлФЯОЉДѓбЇжмжОЛЊНЬЪкЭХЖгНќШеЙЙНЈЕФББкЄЮыЃЈBeimingwuЃЉ? |
| [ЪеВиБОЮФ] ЁОЯТдиБОЮФЁП |
|
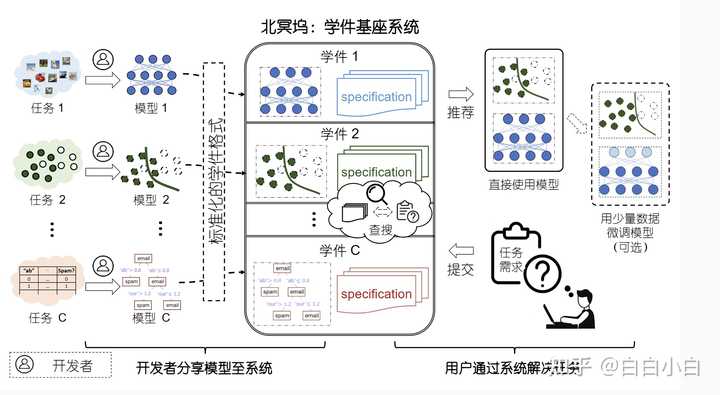
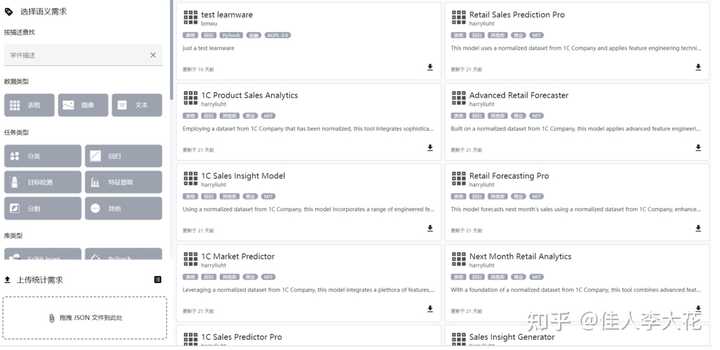
ФЯОЉДѓбЇжмжОЛЊНЬЪкдк 2016 ФъЬсГіСЫбЇМўЃЈlearnwareЃЉИХФюЃЌВЂЛљгкбЇМўвдвЛжжШЋаТЕФЗЖЪНРДНтОіЛњЦїбЇЯАШЮЮёЁЃВЂЧвЃЌбЇМўЗЖЪНЪзДЮЬсГіНЈСЂвЛИіЛљЁ |
|
УЛЯыЕНетУДЖрЭЌбЇЙизЂЁЃ зїЮЊВЮгыепжЎвЛЃЌМђвЊЫЕвЛЯТЮвИіШЫЕФЯыЗЈ 1. бЇМўЪдЭМНтОіЪВУДЮЪЬт ЕБгаДѓСПФЃаЭЛ§РлЯТРДЕФЪБКђЃЌЖдгкЕБЯТвЊЭъГЩЕФбЇЯАШЮЮёЃЌФмПьЫйевЕНЪЪКЯЕФФЃаЭЁЂПьЫйРћгУЯрЫЦЕФФЃаЭРДНтОіЮЪЬтЃЌетЪЧбЇМўвЊДяЕНЕФФПБъЁЃеыЖдетвЛФПБъЃЌФПЧАББкЄЮыНігаЗЧГЃГѕВНЕФИХФюЪЕЯжЃЌЛЙгаКмЖрЮЪЬтгаД§НтОіЃЌвВЯЃЭћгааЫШЄЕФЭЌбЇФмвЛЦ№ВЮгыЁЃ бЇМўЙІФмЯрЙибаОПВПЗжЮФЯзЃК Model Reuse With Reduced Kernel Mean Embedding Specification. TKDE 2023 Identifying Helpful Learnwares Without Examining the Whole Market. ECAI 2023 Identifying Useful Learnwares for Heterogeneous Label Spaces. ICML 2023 Handling Learnwares Developed from Heterogeneous Feature Spaces without Auxiliary Data. IJCAI 2023 Abductive subconcept learning. Science China Information Sciences, 2023 Pre-Trained Model Reusability Evaluation for Small-Data Transfer Learning. NeurIPS 2022 Towards Enabling Learnware to Handle Unseen Jobs. AAAI 2021 Heterogeneous Few-Shot Model Rectification With Semantic Mapping. TPAMI 2021 бЇМўЕФИХФюТлЮФЪЧдк2016ФъЗЂБэЕФЃЌМДЪЙдкНёЬьДѓФЃаЭМЋЮЊЛ№БЌЕФЛЗОГЯТЃЌВщЫбВЂШкКЯЖрИіаЁФЃаЭШЅНтОіЕФЮЪЬтШдШЛЪЧКмгаШЄЕФММЪѕТЗЯпЃЌЧвВЛЫЕТлЮФжаСаГіЕФгХЕуЃЌетЬѕТЗЯпИќНгНќЩњЮяДѓФдЕФНсЙЙЃКИљОнГЁОАашвЊЃЌНЋЯрЙижЊЪЖЯТдиЕНЖЬЦкМЧвфФЃПщжаЃЌНтОіГЁОАЮЪЬтКѓЖЬЦкМЧвфНјаабЁдёадДцДЂЃЌЖЬЦкМЧвфФЃПщЧаЛЛЕНЯТвЛИіГЁОАжаЁЃ 2. ИњhuggingfaceЕФЙиЯЕ жмРЯЪІЙЙЯыЁАбЇМўЁБжЎЪБЃЌЛЙУЛгаhuggingfaceЁЃ Zhi-Hua Zhou. Learnware: On the future of machine learning. Frontiers of Computer Science, 10(4):589ЈC590, 2016. 4243 НёЬьЕФhuggingfaceЪЧвЛИіФЃаЭВжПтЃЌЖјбЇМўЪТвЊЬНЫївЛЬѕВЛЭЌЕФММЪѕТЗЯпЃЌСНепНіНіЪЧдкЁАгаКмЖрФЃаЭЁБЗНУцЯрЫЦЁЃ 3. ЙигкЩЬвЕЛЏЃП дкББкЄЮыжЎЧАЃЌЦфЪЕзщРявбОгыМИИіДѓГЇСЊКЯПЊЗЂСЫЦѓвЕФкВПЕФбЇМўЯЕЭГЃЌНјааСЫвЛЖЈЕФбщжЄЃЌЕЋЭЌЪБвВЗЂЯжЦѓвЕФкВПЕФЯЕЭГЖдгкПЦбаРДЫЕНЯФбШУИќЖрЕФбаОПепКЭЭЌбЇВЮгыЁЃ вђДЫББкЄЮыЪЧЭъШЋПЊдДЕФЯЕЭГЃЌАќРЈЭјеОЧАКѓЖЫЖМШЋВППЊдДСЫЃЌШЮКЮШЫЖМПЩвдздМКВПЪ№ЃЌНігаЮЈвЛФПЕФЃЌОЭЪЧЯЃЭћгаИќЖрЕФбаОПепВЮгыЃЌЖјУЛгаШЮКЮЩЬвЕЛЏЕФФПЕФЁЃвВЯЃЭћгааЫШЄЕФЭЌбЇФмЖдББкЄЮыЯЕЭГКЭЫуЗЈзіГіИФНјЁЃ ЛЙгаКмЖрЭЌбЇЬжТлЩњЬЌЃЌШЗЪЕЩњЬЌЕФаЮГЩЪЧКмФбЕФЃЌПДзХЛЙгаКмЖрВЛПДФкШнЕФЦРТлОЭжЊЕРСЫЁЃВЛЙ§ЮввВПДЕНСЫСэвЛжжПЩФмЃЌДѓСПФЃаЭЕФВњЩњКЭЪЙгУВЂВЛвЛЖЈЪЧШЫВЮгыЕФЃЌвВгаПЩФмЪЧЛњЦїВњЩњЕФЃЌвВаэЛсаЮГЩСэвЛжжЩњЬЌЁЃ СэЭтЩљУївЛЯТЃЌУЛгаЛЈвЛЗжЧЎШЅЭЦЙуЛђепТђЪВУДШШЫб |
|
ПДСЫвЛШІЛиД№ЃЌвРШЛИуВЛЧхетЪЧЪВУДЃЌетПЩФмЪЧББкЄЮыБГКѓЭХЖгвЊНтОіЕФвЛИіжївЊЮЪЬтЃПзмВЛФмвЊЧѓУПИіШЫЖМШЅАбЯрЙиТлЮФЖМЖСвЛБщАЩЁЃ ЕБЬИТлЕНИњhuggingfaceЕФЙиЯЕЪБЃЌжЛЪЧЫЕЁАжмРЯЪІЬсГіЕФЪБМфИќдчЁБЃЌетЫЦКѕУЛгаШЮКЮвтвхЃЌДѓМвЙизЂЕФЪЧЕНЕзгаЪВУДгУЃЌКУВЛКУгУЃЌЖјВЛЪЧдчВЛдчЃЌПіЧвЛњЦїбЇЯАФЃаЭЦНЬЈРрЫЦЕФИХФюгЩРДвбОУСЫЃЌвВВЛЪЧЪВУДЬиБ№ЕФДДаТЁЃ |
|
|
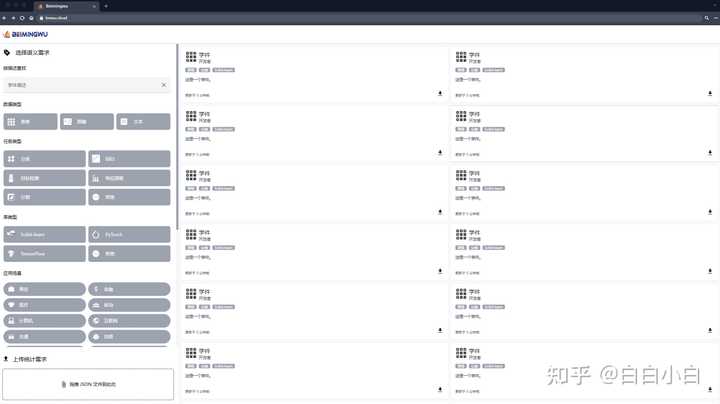
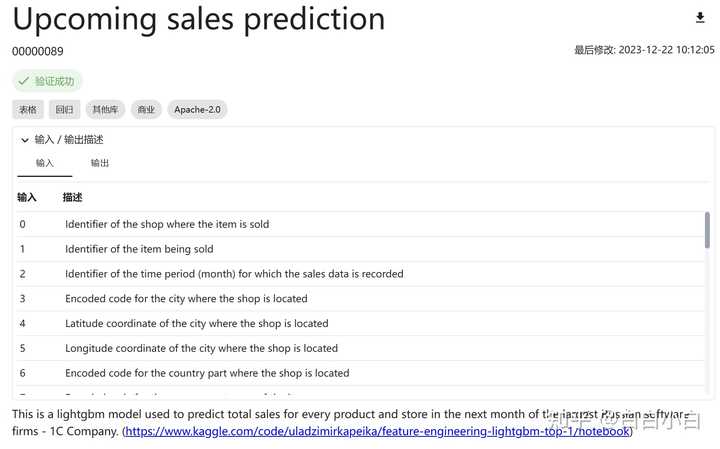
ЭјеОжївГЧАЖЫзіЕФКмгаШЄАЁ дкДжТдЖССЫТлЮФВЂЧзздЬхбщСЫЭјеОжЎКѓЃЌЖЗЕЈЗЂБэвЛаЉздМКЕФЦРМлЁЃ ТлЮФСДНгЃК2401.14427.pdf (arxiv.org) ЪЭвх бЇМў learnware ШэМўЪЧsoftwareЃЌгВМўЪЧhardwareЃЌДѓУћЖІЖІЕФШэЙЄСьгђЪщМЎЁЖШЫМўЁЗдУћНаpeoplewareЃЌжИЕФЪЧКЭЭХЖгЙмРэжаКЭШЫЯрЙиЕФвЛЧаЮЪЬтЁЃФЧбЇМўздШЛКЭбЇЯрЙиЁЃ бЇМўгЩадФмгХСМЕФЛњЦїбЇЯАФЃаЭКЭУшЪіФЃаЭЕФЙцдМзщГЩЁЃ ЙцдМ specification ЙцдМПЬЛСЫФЃаЭЕФФмСІЃЌЪЙЕУФЃаЭдкЮДРДФмЙЛИљОнгУЛЇашЧѓБЛГфЗжЪЖБ№КЭИДгУЁЃЙцдМгЩСНВПЗжЙЙГЩЃКгявхЙцдМЭЈЙ§ЮФБОУшЪіФЃаЭЕФЙІФмЃЌЖјЭГМЦЙцдМПЬЛФЃаЭЫљдЬКЌЕФЭГМЦаХЯЂЁЃ |

|
|
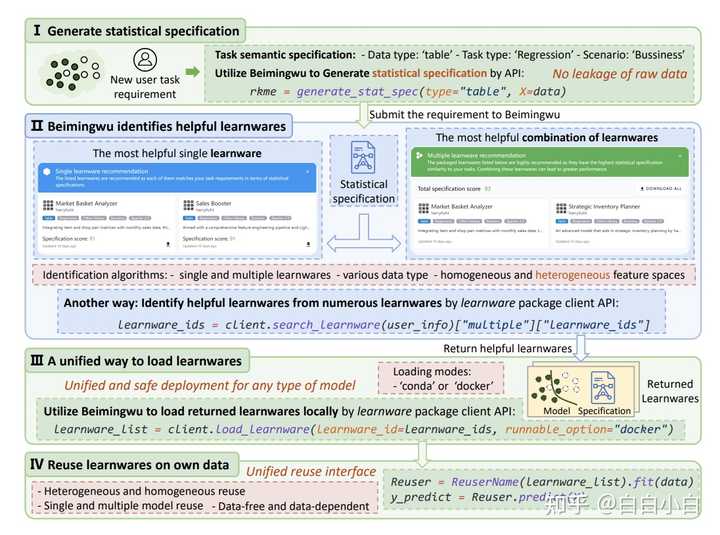
бЇМўгыЙцдМ МђЕЅРДЫЕЃЌбЇМў = ФЃаЭБОЩэ + УшЪіФЃаЭЙІФмЕФЮФБОаХЯЂЃЈгявхЙцдМЃЉ+УшЪіЪ§ОнМЏЕФЭГМЦаХЯЂЃЈЭГМЦЙцдМЃЉ ОйИіР§згЃЌвдЯТЪЧвЛИіФЃаЭКЭЫќЕФЪ§ОнМЏаХЯЂЃЌАќРЈЪфШыЪфГіЕШЃК |
|
|
ЭГМЦЙцдМдкНчУцжаВЂУЛгаЬхЯжЃЌИљОнТлЮФжаЕФУшЪіЃЌЪЧЛљгкRKME (Reduced Kernel Mean Embedding)ЪЕЯжЕФЃЌЪЪгУгкБэИёЁЂЭМЯёКЭЮФБОЪ§ОнЁЃЪЙгУзюДѓЦНОљВювьЃЈMMDЃЉМЦЫуПЩвдЦРЙРЯрЭЌРраЭЕФRKMEЭГМЦЙцдМЕФЯрЫЦадЁЃКЭ2016ФъжмРЯЪІЕФЮФеТвЛжТЁЃ [2210.03647] Learnware: Small Models Do Big (arxiv.org) ШчДЫвЛРДБуФмДѓИХРэЧхетИігІгУЕФТпМСЫЁЃ |
|
|
ЦНЬЈФкЛ§РлЕФДѓСПЕФбЇМўЁЃЕБгУЛЇвЊНтОівЛИіаТЕФЛњЦїбЇЯАШЮЮёЪБЃЌЫћПЩвдЯђББкЄЮыЬсНЛздМКЕФашЧѓЃЌШЛКѓЯЕЭГНЋИљОнЙцдМДгжкЖрбЇМўжаЪЖБ№КЭзщзАвЛаЉгаАяжњЕФбЇМўЃЌВЂЗЕЛиИјгУЛЇЁЃ зюМЋЖЫЕФЧщПіЃЌвЛИіЩЖвВВЛЖЎЕФМЦЫуЛњаЁАзЃЌРДББкЄЮыЃЌЫЕЃКЁАЮвМвГЄСЫКУЖрВннЎЃЌЯывЊвЛИіФмЪЖБ№КьВннЎКЭТЬВннЎЕФЛњЦїЁБЁЃФЧзюжеОЭФмЗЕЛивЛИіЫћТњвтЕФГЬађЃЌЭъГЩЫћЕФашЧѓЁЃ |
|
|
ИљОнТлЮФЃЌЕБЧАББкЄЮыНігадМ1100ИіДгПЊдДЪ§ОнМЏЙЙНЈЕФбЇМўЃЌКИЧЕФГЁОАгаЯоЁЃ вЛаЉЮЪЬт здШЛЖјШЛЕФЃЌЛљгкетИіЙ§ГЬЃЌЮвУЧЛсгавЛаЉЮЪЬтЁЃ вдЯТЮЪЬтНіЪЧПДЮФеТЪБЕФвЛаЉЫМПМЃЌШчгаЦЋЦФЃЌЧыжИе§ЁЃ КЭhuggingfaceЕШгаКЮВЛЭЌЃП ИіШЫИаОѕЪЧзіСЫЖдашЧѓКЭашЧѓЪ§ОнЕФЬиеїЬсШЁЃЌгУРДВщевЖдгІЕФбЇМўЃЌвдМАзіСЫЬсНЛЁЂПЩгУадВтЪдЁЂзщжЏЁЂЙмРэЁЂЪЖБ№ЁЂВПЪ№КЭжигУвЛеОЪНЕФСїГЬЁЃЕЋЪЧhuggingfaceЛЙЬсЙЉСЫdemoдкЯпбщжЄЕФПеМфЁЃ 2. ШчКЮзіЕНзщзАбЇМўЃП ЕБвЛИіШЮЮёЩцМАЖрИіФЃаЭЪБЁЃЮФеТжаЫЕЪЙгУСЫalignerНјааФЃаЭжЎМфЪ§ОнЮЌЖШЕФЖдЦыЃЌЕЋЪЧаЇЙћДцвЩЁЃ |

|
|
3. ЪЧЗёецЕФПЩвдгПЯжЃП ПЩФмЪЧПДЕФЪБКђЪшТЉСЫЃЌдкСїГЬжаЃЌЫЦКѕУЛгавЛИіПЩвдНјааГжајбЇЯАКЭГжајИќаТЕФЙ§ГЬЃЌФЧУДЪЧЗёецЕФПЩвдГіЯжжївГжадЄЦкЕФгПЯжЯжЯѓЃПвђЮЊетбљЕФЛАЃЌЫЦКѕКЃСПЪ§ОнКЭЩйСПЪ§ОнвВУЛгаЬЋДѓЕФЧјБ№ 4. ФЃаЭФкВЮЪ§вВЪєгкЙцдМТ№ЃП ЪЕМљЙ§ГЬжаЃЌОГЃЛсХіЕНЃЌШчЙћЪ§ОнБфСЫЃЌФЃаЭГЌВЮПЩФмашвЊвЛаЉЕїећРДЪЪгІЃЌБШШчЮоМрЖНжаKmeansЕФKжЕЃЌЛђепбЇЯАТЪЕШЃЌетаЉШчЙћПЊЪМЪБУЛгазїЮЊЬиеїБэЪОдкбЇМўжаЃЌКѓУцШчКЮФмЪЪгІЕїећЃП 5. Ъ§ОнЙЄГЬЮоЗЈБмУтЃП ШчЙћашвЊЮвЩЯДЋЪ§ОнРДбАевЪЪКЯЕФбЇМўЃЌФЧБиШЛЪЧЮвИјЕФЪ§ОнОЭЪЪКЯетИібЇМўЁЃФЧШчЙћЮввбОгаКЯЪЪЕФЪ§ОнСЫЃЌЪЧВЛЪЧДњБэЮвЖдетИіШЮЮёгаСЫвЛЖЈЕФРэНтСЫЃЌвбОжЊЕРЭъГЩШЮЮёашвЊФФаЉЪ§ОнСЫЁЃЬШШєЮвЛЙВЛЭъШЋСЫНтЃЌЬсЙЉвЛХњЮДОећРэЕФЪ§ОнЃЌЪЧЗёФЃаЭЭЦМіОЭВЛзМШЗСЫЃП |
|
ДђПЊЭјвГПДСЫвЛблЃЌЯызХздМКЧЁКУгаНЬг§ЭјгЪЯфЃЌИЯНєзЂВсСЫвЛИізМБИГЂГЂЯЪЃК |
|
|
ЭјвГГфТњСЫвЛжжМЋМђЗчЃЌПДЕУГіРДГіздПЦбаЭХЖгжЎЪжЁЃВЛЙ§НіДгЭјвГЩЯРДПДгааЉВЛжЊЫљвдЃЌПДВЛУїАзЕНЕзгІИУдѕбљгУвдМАгаЪВУДгУЃЌЫљвдЮвОіЖЈЛЙЪЧЯШШЅПДПДТлЮФбЇЯАвЛЯТЁЃ |

|
|
ТлЮФзмНсЕФBeimingwuЙБЯзжївЊАќРЈвдЯТМИЕуЃК МђЛЏаТШЮЮёФЃаЭПЊЗЂЃКBeimingwuЯЕЭГЭЈЙ§бЇМўЗЖР§ЃЌЯджјМђЛЏСЫЮЊгІЖдаТШЮЮёЙЙНЈЛњЦїбЇЯАФЃаЭЕФЙ§ГЬЁЃгУЛЇПЩвдгУМИааДњТыПьЫйВПЪ№ИпадФмФЃаЭЃЌЖјВЛашвЊДѓСПЪ§ОнКЭзЈМвжЊЪЖЃЌЭЌЪББЃЛЄЪ§ОнвўЫНЁЃМЏГЩКЭПЩРЉеЙЕФМмЙЙЩшМЦЃКBeimingwuЬсЙЉСЫвЛИіЭГвЛЕФбЇЯАЦїНсЙЙКЭМЏГЩЕФЯЕЭГв§ЧцМмЙЙЃЌжЇГжбЇЯАЦїЕФећИіЙ§ГЬЃЌАќРЈЬсНЛЁЂВтЪдЁЂЙмРэЁЂЪЖБ№ЁЂВПЪ№КЭжигУЁЃетИіМмЙЙПЩвдаЕїДѓСПбЇЯАЦїЃЌБугкЮДРДбаОПЁЃПЊдДбЇЯАЦїЖдНгЯЕЭГКЭЭГвЛгУЛЇНчУцЃКBeimingwuЕФКЫаФв§ЧцзїЮЊбЇМўАќПЊдДЗЂВМЃЌжЇГжМЦЫуКЭЫуЗЈЗНУцЁЂЯЕЭГКѓЖЫКЭгУЛЇНчУцЃЈАќРЈЭјвГКЭУќСюааПЭЛЇЖЫЃЉЃЌжМдкНЈСЂбЇМўЩњЬЌЯЕЭГЁЃеыЖдВЛЭЌГЁОАЕФШЋЙ§ГЬЛљЯпЫуЗЈЕФЪЕЯжКЭЦРЙРЃКBeimingwuЪЕЯжСЫвЛЯЕСаЛљЯпЫуЗЈЃЌжЇГжДІРэБэИёЁЂЭМЯёКЭЮФБОЪ§ОнЕФФЃаЭЃЌВЂНјааСЫЪЕжЄбаОПЦРЙРЃЌетаЉЖМЪЧЙЋПЊЕФЃЌвдБуЮДРДбаОПЁЃ НВецЃЌЮоТлПДдЮФЕФгЂЮФЃЌЛЙЪЧЗвыГЩжаЮФШЯецРэНтЃЌШдШЛгажжУдУдК§К§ЁЂВЛжЊЫљдЦЕФИаОѕЃЌЯызХЪЕМљВХФмГіецжЊЃЌЮвгжЗЕЛиСЫBeimingwuЕФжївГбаОПЁЃ ЦфжаЁАЮФЕЕЁБАДХЅЕуЛїКѓгавЛаЉОпЬхЕФЪЙгУЫЕУїЁЊЁЊ |
|
|
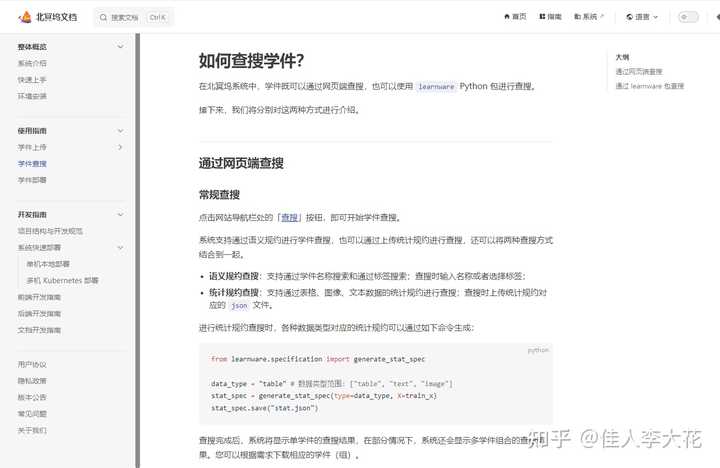
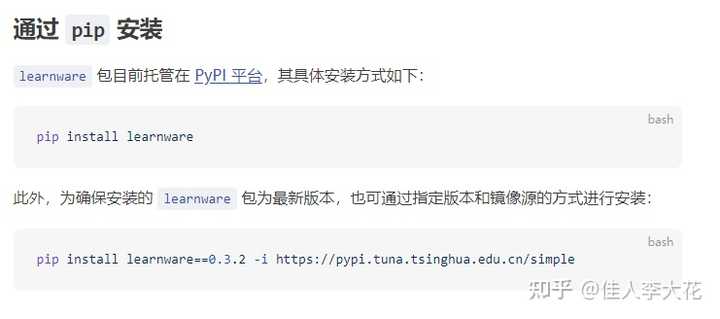
АВзАlearnwarePython АќЪЧЕквЛВНЃЌАДееЫЕУїМДПЩЫГРћЪЕЯжЃК |
|
|
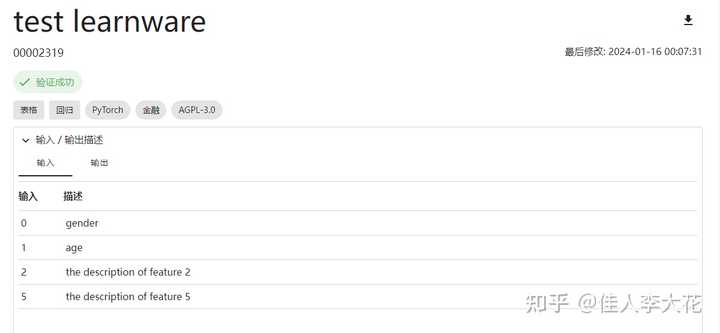
ХфжУКУЛЗОГКѓЃЌЮвЫцБуевСЫвЛИіВтЪдбЇМўзїЮЊГЂЪдЃК |
|
|
ПЩЯЇвЛжББЈДэЃК |

|
|
днЪБУЛгааЫШЄМЬајбаОПСЫЃЌЯЃЭћЮДРДПЩвдЖдгкУПИібЇМўЕФЪфШыЪфГіашЧѓвдМАЛЗОГХфжУгаИќЧхЮњЕФЫЕУїЃЌЗёдђгУЦ№РДЛЙЪЧгааЉТщЗГЕФЁЃ ВЛЙ§етИіЯЕЭГЕФДѓжТЫМТЗЕЙЪЧРэНтСЫЃЌОЭЪЧЯЃЭћДѓМвЩЯДЋИїжжЩцМАБэИёЁЂЭМЯёЁЂЮФБОЕФЛњЦїбЇЯАФЃаЭЃЌЙЉЦфЫћгаРрЫЦгІгУашЧѓЕФгУЛЇЃЌОЙ§МђЕЅЕФаоИФКѓжБНгЪЙгУЁЃ етИіФПБъЬ§Ц№РДКмСюШЫаЫЗмЃЌВЛЙ§ОЭЯЕЭГЕФЯжзДРДПДЃЌЮДРДПжХТЛЙашвЊгаДѓСПЕФгХЛЏЙЄзїЃЌВХФмГЩЮЊGitHubЛђhuggingfaceжЎРрЕФЁАЩЕЙЯЪНЁБФЃаЭМьЫїЯЕЭГЁЃ |
|
ЪЕдкУЛЯыЕНгаетбљЕФШШЖШКЭЙизЂЁЃ еыЖдвЛаЉЮЪЬтЃЌЮвИљОнбаЗЂЕФЪЕМЪОРњЗжЯэвЛаЉИіШЫЕФПДЗЈЃЌВЙГфвЛЯТгсРЯЪІ @гсбя ЕФЫЕУїЁЃ ЦРТлРязюжївЊЕФЮЪЬтЪЧЃКЮЊЪВУДвЊзібЇМўЯЕЭГЃПИњ HuggingFace ЕФЙиЯЕЃПЮЊЪВУДвЊзіДѓСПЕФЙЄГЬЃП ЪзЯШЃЌВЛЕУВЛГаШЯЃЌбаЗЂЯЕЭГЖдгкзібаОПЕФШЫЪЧвЛИіКмРлЕФЪТЖљЃЌвђЮЊШЗЪЕЩцМАДѓСПЕФЙЄГЬПЊЗЂЃЌЖјПЦбаШЫзюПДжиЕФЛЙЪЧ paperЁЃШЛЖјЙ§ШЅЕФМИФъРяЃЌвђЮЊбЇМўЫуЗЈЕФбаОПЃЌЮвУЧж№НЅШЯЧхСЫдаЭПЦбаЯЕЭГЕФбаЗЂЪЧВЛЕУВЛзіЕФЃЌетРявВХхЗўжмРЯЪІЕФЧАеАадЁЃЦфЪЕбЇНчбаЗЂдаЭЯЕЭГЕФЪТВЂВЛЯЪМћЃЌгШЦфЪЧЙњМЪЩЯаэЖрЪьжЊЕФЯЕЭГзюГѕдаЭбаЗЂГЂЪдЖМЦ№дДгкПЦбаЁЂНЬбЇСьгђЃЌЭљЭљвВЪЧвђЮЊДДаТаЭЕФГЂЪдУЛАьЗЈЪЙгУвбгаЙЄОпРДЭъГЩЁЃ ДгДѓМвЪьжЊЕФ HuggingFace ЫЕЦ№ЃКHuggingFace ЕФФЃаЭПтЩњЬЌвбОЗЧГЃГЩЙІЃЌВЂЧвШЗЪЕЪЧВњЦЗЁЂЙЄГЬЧ§ЖЏЕФЃЌБОжЪЕФМмЙЙЪЧЭЈЙ§ Git ЙмРэЕФФЃаЭдЖГЬЭаЙмЦНЬЈЃЌПЩвдЫЕФЃаЭгы HuggingFaceЃЌЛљБОЙмРэЗНЪНЕШЭЌгкДњТыВжПтгы GithubЁЃУПИіФЃаЭвРШЛЪЙгУДњТыВжПтЕФЗНЪНЃЌЭЈЙ§ README НщЩмЦфЪЙгУЗНЪНЁЂадФмЁЂЩѕжСАщЫцвЛаЉФЃаЭЕФаћДЋЃЌНјЖјгУЛЇЯывЊЙЙНЈздМКЕФФЃаЭЪБЃЌПЩвдЯёШЅ Github ПДПДЪЧЗёгадьКУЕФТжзгвЛбљЃЌЭЈЙ§ READMEЁЂЯТдиСПЕШШЅ HuggingFace ЬєбЁФЃаЭЁЃ ШЛЖјЃЌдчдк 2016 ФъЃЌжмРЯЪІдкбЇМўЕФТлЮФ[1]жаЃЌЫМПМЕНЃКЫцзХЛњЦїбЇЯАЗЂеЙЃЌЩюШыЕНИїИіСьгђЃЌгХжЪФЃаЭНЋЛсдНРДдНЖрЃЌЭЈЙ§ЙЙНЈвЛИіДѓЕФФЃаЭЗжЯэЦНЬЈЃЌПЩвдЗНБуЕиНтОіаэЖрЛњЦїбЇЯАжаЕФЮЪЬтЁЃШЛЖјЭЌЪБЃЌЕБФЃаЭЙцФЃЗЧГЃХгДѓжЎКѓЃЌНіНіЙЙНЈвЛИіЭаЙмЦНЬЈКмФбТњзугУЛЇашЧѓЃЌвђЮЊЦеЭЈгУЛЇДЫЪБвбОКмФбЗжБцФФаЉФЃаЭЖдздМКЕФШЮЮёеце§гагУСЫЁЃЯжЪЕвВШЗЪЕШчДЫЃЌHuggingFace зЊблМфЃЌвбОгаНќ 50 ЭђФЃаЭЃЌЮвМЧЕУ 2022 ФъЪБжЛга 5 ЭђзѓгвЃЌвЛФъЖрЗСЫЪЎБЖЃЌЦЦАйЭђжИШеПЩД§ЁЃМДЪЙЭЈЙ§ЙиМќДЪЫбЫїЃЌПЩФмвРШЛДѓСПФЃаЭеЙЪОдкУцЧАЃЌФФИіФЃаЭЁЂЛђепФФаЉФЃаЭЕФзщКЯЪЧзюЪЪКЯгУЛЇЕБЯТШЮЮёЕФЃП гкЪЧАДЮвЕФРэНтЃЌетЪЧЮЊЪВУДбЇМўжаЩшМЦСЫ"ЙцдМ"ЁЃЭЈЙ§ЙцдМРДдЄЯШПЬЛФЃаЭЕФФмСІЃЌДгЖјеыЖдгУЛЇашЧѓЃЌЛљгкЙцдМПЩвдздЪЪгІЕиДгХгДѓЕФЦНЬЈжаЦЅХфЕНЧБдкгагУЕФвЛИіЛђвЛзщФЃаЭЁЃreadme ЮФЕЕвВПЩвдПДзївЛжжЛљгкгявхУшЪіЕФЙцдМЃЌЕЋЪЧЛЙВЛЙЛЃЌвђЮЊФЃаЭВЛЭЌгкЮФБОЁЂДњТыЃЌБОжЪЩЯЪЧвЛИіЗЧГЃИДдгЕФКЏЪ§ЃЌЯывЊПЬЛЧхГўЃЌЭГМЦЙЄОпЗЧГЃживЊЁЃЖјЧвЙцдМЕФвЊЧѓКмИпЃЌМШвЊФмПЬЛФЃаЭЫљЖдгІЕФКЏЪ§ЕФЬиГЄЃЌДгЖјгіЕНаТШЮЮёКѓЃЌФмЙЛЛљгкЙцдМШЅЦЅХфКЯЪЪЕФФЃаЭЃЛСэвЛЗНУцЃЌЙцдМгжВЛФмБЉТЖПЊЗЂепЕФдЪМбЕСЗЪ§ОнЃЌЗёдђаэЖрПЊЗЂепВЛдйдИвтЗжЯэФЃаЭЁЃжЎЧАзщРявВзіЙ§аэЖрЙцдМЕФГЂЪдЃЌЯждкББкЄЮыжаЪЙгУЕФЪЧ RKME ЙцдМЃЌгХЕуЪЧЭЈЙ§ MMD ОрРыЕФгХЛЏЃЌФмвЛЖЈГЬЖШЩЯПЬЛФЃаЭЩУГЄЕФЪ§ОнЗжВМКЭШЮЮёЕФЪ§ОнЗжВМЃЌЭЌЪБЮвУЧЗЂЯжПЩФмДгРэТлЩЯжЄУїЫќЖддЪМЪ§ОнОпгавЛЖЈЕФвўЫНБЃЛЄФмСІ (...ПЩвдЦкД§ЯТЮДРДЙЄзї:) )ЁЃ ЗДЙ§РДЃЌРэТлЩЯПЩвджЄУїЃЌШчЙћУЛгаетбљЕФЙцдМЃЌНігавЛИіХгДѓЕФФЃаЭПтЃЌЖдгкаэЖргУЛЇШЮЮёЃЌЪЧЮоЗЈИпаЇЕиВщЫбЁЂЦЅХфЕНКЯЪЪЕФвЛзщФЃаЭЕФЃЌЩѕжСжЛФмБЉСІЕиЫбЫїГЂЪдЁЂгШЦфЪЧФЃаЭЕФзщКЯЃЌетдкФЃаЭПтЙцФЃХгДѓжЎКѓЪЧЮоЗЈНгЪмЕФЁЃСэвЛЗНУцЃЌЮвУЧЗЂЯжЙцдМвВгааэЖрЦфЫћЕФКУДІЃЌВЛНіЪЧВЛдйашвЊГЂЪдФЃаЭЃЌР§ШчЖдгкВЛЯыБЉТЖЪ§ОнЕФгУЛЇЃЌвВПЩвдЭЈЙ§ЖдШЮЮёзіЭГМЦЙцдМРДВщЫбКЯЪЪЕФФЃаЭВПЪ№ЕНБОЕиЃЌЖјЮоашЩЯДЋдЪМЪ§ОнЃЛФЃаЭдіЖрКѓПЩвдЛЅЯр"азїЙЕЭЈ"ЁЂбнНјЙцдМЃЌЪЙЙцдМЖдФЃаЭФмСІЕФПЬЛИќзМШЗЃЛвдМААяжњФЃаЭзщКЯЁЂИДгУЃЛЕШЕШВЛзИЪіЁЃ гкЪЧЃЌЮЊСЫКѓајЕФбЇМўбаОПЃЌЮвУЧдНРДдНашвЊвЛЬзЃЌгЩЙцдМЙсДЉЪМжеЕФаТЕФЯЕЭГЦНЬЈМмЙЙЃКвдЙцдМЮЊКЫаФРДзщжЏФЃаЭ (ШЗЧаЕиЫЕЪЧЭГМЦЙцдМ)ЃЌФмЙЛеыЖдгУЛЇашЧѓздЪЪгІЦЅХфФЃаЭЃЌЭГвЛгУЛЇНгПкКЭбЇМўНсЙЙЃЌзїЮЊбЇМўЕФПЦбаЦНЬЈЃЛЕЋЕБЯТвбгаЕФФЃаЭБЛЖЏЭаЙмЦНЬЈдЖЮоЗЈжЇГжетИіашЧѓЁЃЭЌЪБЃЌетИіаТМмЙЙвВЪЙЕУЮДРДФЃаЭЪ§СПХгДѓКѓФмЙЛвРШЛЗНБуЕиЮЊгУЛЇЬсЙЉЗўЮёЁЂЦЅХфФЃаЭГЩЮЊПЩФмЁЃЖјетИіМмЙЙжЛФмЮвУЧздМКРДЭЦЖЏЃЌвђЮЊВЛНіашвЊЙЄГЬПЊЗЂЃЌЦфжаашвЊаэЖраТЕФбаЗЂЁЂНгПкЩшМЦЁЃЮвУЧУЛгаДђЫуНЋББкЄЮызіГЩ"ЩЬвЕВњЦЗ"ЃЌЖјЪЧгУзїбЇМўбаОПЕФГѕВНПЦбаЦНЬЈЃЌгХЯШУцЯђбЇЪѕНчЃЌзїЮЊГѕВНЕФАцБОЃЌЮвУЧШЯЮЊЛљБОТњвтСЫЁЃгЩгкЭјеОжЇГжЛЙБШНЯГѕВНЃЌЮвУЧЛЖгЖдЯЕЭГКЭбаОПИааЫШЄЕФХѓгбЙизЂвЛЯТЮвУЧЕФПЊдДДњТыВжПт:) ЯЕЭГЧАКѓЖЫЃК GitLink | ШЗЪЕПЊдД ЯЕЭГв§ЧцЁЂПЦбаАќЃК GitLink | ШЗЪЕПЊдД ШчЭЌЦРТлЧјДѓМвЫљЫЕЃЌбаОПжЎЭтЃЌЩњЬЌЙЙНЈЪЧМЋЦфРЇФбЕФЃЌЮвУЧздМКЕФСІСПвВЪЕдкгаЯоЁЂдкЭЦЖЏбЇМўПЦбажЎЭтвВКмФбШЋСІгУдкЩњЬЌЙЙНЈЩЯЃЌЫљвдББкЄЮыЪЧЭъШЋПЊдДЕФЁЂЗЧжааФЛЏЕФЃЌШЮКЮШЫЁЂЦѓвЕЖМПЩвдВПЪ№ЁЂИФНјЃЌРДЙЙНЈЩчЧјЁЃЮвУЧжЛЪЧДюКУСЫКЫаФМмЙЙЁЂНгПкКЭЛљДЁЪЕЯжЃЌЮЊетМўЪТПЊСЫИіЭЗЁЃЮвУЧНгЯТРДЛсЛљгкИУЦНЬЈГжајЭЦНјКЫаФЫуЗЈЕФбаОПЁЃ зюКѓЃЌЮЊСЫЗўЮёПЦбаЃЌЮвУЧЕФДѓСПОЋСІЛЈдкНгПкЕФПЩРЉеЙадЩЯЃЌЪЙЮДРДПЩФмЕФЫуЗЈФмЙЛМЏГЩдкФкЁЃЖјЮЊСЫЮШЖЈдЫааЃЌЕБЧАЯЕЭГЪЙгУЕФЫуЗЈНіНіЪЧbaselineЃЌЛЙгавЛаЉе§дкбаОПЕФЫуЗЈКЭвбЗЂБэЕФЙЄзїЛсж№ВНГЂЪдТфШыЯЕЭГЃЌГжајИФНјЯЕЭГКЫаФЙІФмЁЃЛЖгДѓМввЛЦ№РДИФЩЦ:) ДЫЭтЃЌБОЛиД№жївЊеыЖдЮЪЬтжаЬсЕНЕФзюаТЕФЯЕЭГТлЮФЃЌУЛгаЬивтНщЩмбЇМўПђМмДјРДЕФЦфЫћгХЪЦЃЌЖдбЇМўећЬхИааЫШЄЕФХѓгбПЩвдВЮПМТлЮФ[2]ЃЌЛђНјвЛВНгыЮвУЧбаЗЂЭХЖгНЛСї (bmwu-support@lamda.nju.edu.cn)~ [1] Z.-H. Zhou. Learnware: on the future of machine learning. Frontiers of Computer Science, 2016, 10(4): 589ЈC590 [2] Z.-H. Zhou and Z.-H. Tan. Learnware: Small models do big. Science China Information Sciences, 2024, 67(1): 112102. |
|
|
| [ЪеВиБОЮФ] ЁОЯТдиБОЮФЁП |
| НЬг§аХЯЂ зюаТЮФеТ |
| ЙЂЭЌбЇВЛШЅБЌСЯздМКЕФФИаЃМЊСжДѓбЇЕФдвђЪЧ |
| РюаТвАЫЕЃЌЁАТщЪЁРэЙЄбЇдКДѓвЛбЇЩњЃЌЫЎЦНВЛ |
| ЮЊЩЖШЫДѓДЫЧАШЯЖЈНЏЗНжлВЛДцдкбЇЪѕВЛЖЫааЮЊ |
| ЮЊЪВУДНЫеБОПЦЬсЧАХњЭЖЕЕЯпЃЌжаЙњШЫУёЙЋАВ |
| ШчКЮЦРМлШЫДѓГЗЯњНЏЗНжлЫЖЪПбЇЮЛЃП |
| ЭјДЋДѓСЌРэЙЄФГбЇдКСьЕМСЌајСНФъЮдЕзеаЩњШК |
| аЁбЇЕФГЩМЈгаКмДѓЕФЦлЦадЃЌЕНСЫГѕжаОЭЛсга |
| ЮЊЪВУДЩэБпгХауЕФРэПЦЩњНќКѕШЋВХЃЌЮФПЦЩњжЛ |
| ЖрТзЖрДѓбЇХХУћМгФУДѓЕквЛЃЌЮЊЪВУДКмЖрШЫВЂ |
| ХАУЈПМЩњВЮМгРМДѓбаОПЩњЕїМСУцЪдЃЌЮДЯжЩэЫМ |
| ЩЯвЛЦЊЮФеТ ЯТвЛЦЊЮФеТ ВщПДЫљгаЮФеТ |
|
|
|
|
ЙХЕфУћжј
УћжјОЋбЁ
ЭтЙњУћжј
ЖљЭЏЭЏЛА
ЮфЯРаЁЫЕ
УћШЫДЋМЧ
бЇЯАРјжО
ЪЋДЪЩЂЮФ
ОЕфЙЪЪТ
ЦфЫќдгЬИ
аЁЫЕЮФбЇ ПжВРЭЦРэ ИаЧщЩњЛю ЦПаА дДДаЁЫЕ аЁЫЕ ЙЪЪТ ЙэЙЪЪТ ЮЂаЁЫЕ ЮФбЇ ЕЂУР ЪІЩњ ФкЯђ ГЩЙІ фьЯцЯЊдЗ ОЩЯяѓЯИш ЛЈЧЇЙЧ НЃРД ЭђЯржЎЭѕ ЩюПеБЫАЖ ЧГЧГМХФЏ yyаЁЫЕАЩ ДЉдНаЁЫЕ аЃдАаЁЫЕ ЮфЯРаЁЫЕ бдЧщаЁЫЕ аўЛУаЁЫЕ ОЕфгяТМ Ш§Йњбнвх ЮїгЮМЧ КьТЅУЮ ЫЎфАДЋ ЙХЪЋ взО КѓЙЌ ЪѓУЈ УРЮФ ЛЕЕА ЖдСЊ ЖСКѓИа ЮФзжАЩ ЮфЖЏЧЌРЄ екЬь ЗВШЫаоЯЩДЋ ЭЬЪЩаЧПе ЕСФЙБЪМЧ ЖЗЦЦВдёЗ ОјЪРЬЦУХ СњЭѕДЋЫЕ жяЯЩ ЪќХЎгаЖО ЙўРћВЈЬи бЉжаКЗЕЖаа жЊЗёжЊЗёгІЪЧТЬЗЪКьЪн МЋЦЗМвЖЁ Сњзх аўНчжЎУХ УЇЛФМЭ ШЋжАИпЪж аФРэзя аЃЛЈЕФЬљЩэИпЪж УРШЫЮЊЯк Ш§Ьх ЮвгћЗтЬь ЩйФъЭѕ ОЩЯяѓЯИш ЛЈЧЇЙЧ НЃРД ЭђЯржЎЭѕ ЩюПеБЫАЖ ЬьАЂНЕСй жиЩњЬЦШ§ зюЧППёБј СкМвЬьЪЙДѓШЫАбЮвБфГЩЗЯШЫетЪТ ЖЅМЖЦњЩй ДѓЗюДђИќШЫ НЃЕРЕквЛЯЩ вЛНЃЖРз№ НЃЯЩдкДЫ ЖЩНйжЎЭѕ ЕкОХЬиЧј ВЛАмеНЩё аЧУХ ЪЅац |
|
|
| ЭјеОСЊЯЕ: qq:121756557 email:121756557@qq.com |